在实际的例子中来学习设计模式。
0. UML
| 名称 | 解释 | 图片 |
|---|---|---|
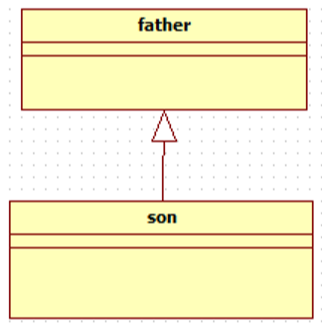
| 泛化 | 泛化是一种一般与特殊、一般与具体之间关系的描述, 具体描述建立在一般描述的基础之上,并对其进行了扩展。 在java中用来表示继承的关系。 |
 |
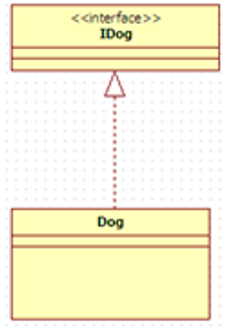
| 实现 | 实现是一种类与接口的关系, 表示类是接口所有特征和行为的实现, 在程序中一般通过类实现接口来描述 |
 |
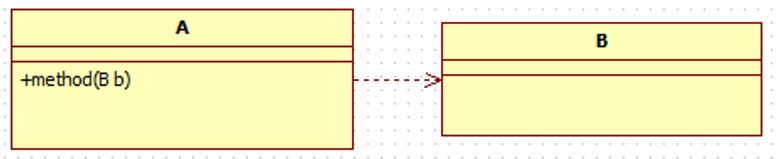
| 依赖 | 是一种使用的关系,即一个类的实现需要另一个类的协助。 java中,方法参数需要传入另一个类的对象,就表示依赖这个类。 表示方法:虚线箭头,类A指向类B。 |
 |
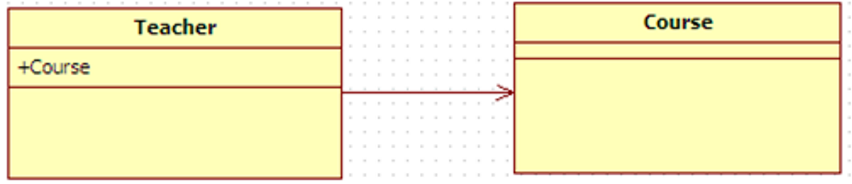
| 关联 | 表示类与类之间的联接,它使一个类知道另一个类的属性和方法, 这种关系比依赖更强、不存在依赖关系的偶然性、关系也不是临时性的,一般是长期性的。 |
 |
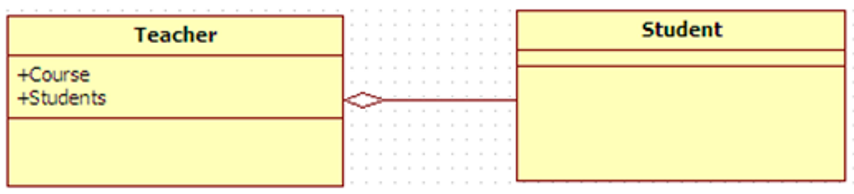
| 聚合 | java中一个类的全局变量引用了另一个类,就表示关联了这个类聚合关联关系的一种特例,是强的关联关系。 聚合是整体和个体之间的关系,即has-a的关系, 整体与个体可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享。 程序中聚合和关联关系是一致的,只能从语义级别来区分; |
 |
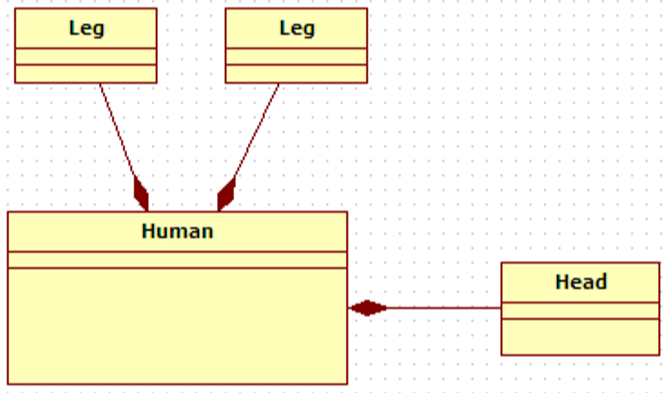
| 组合 | 组合也是关联关系的一种特例。组合是一种整体与部分的关系,即contains-a的关系,比聚合更强。 部分与整体的生命周期一致,整体的生命周期结束也就意味着部分的生命周期结束,组合关系不能共享。 程序中组合和关联关系是一致的,只能从语义级别来区分。 |
 |
1. 设计原则
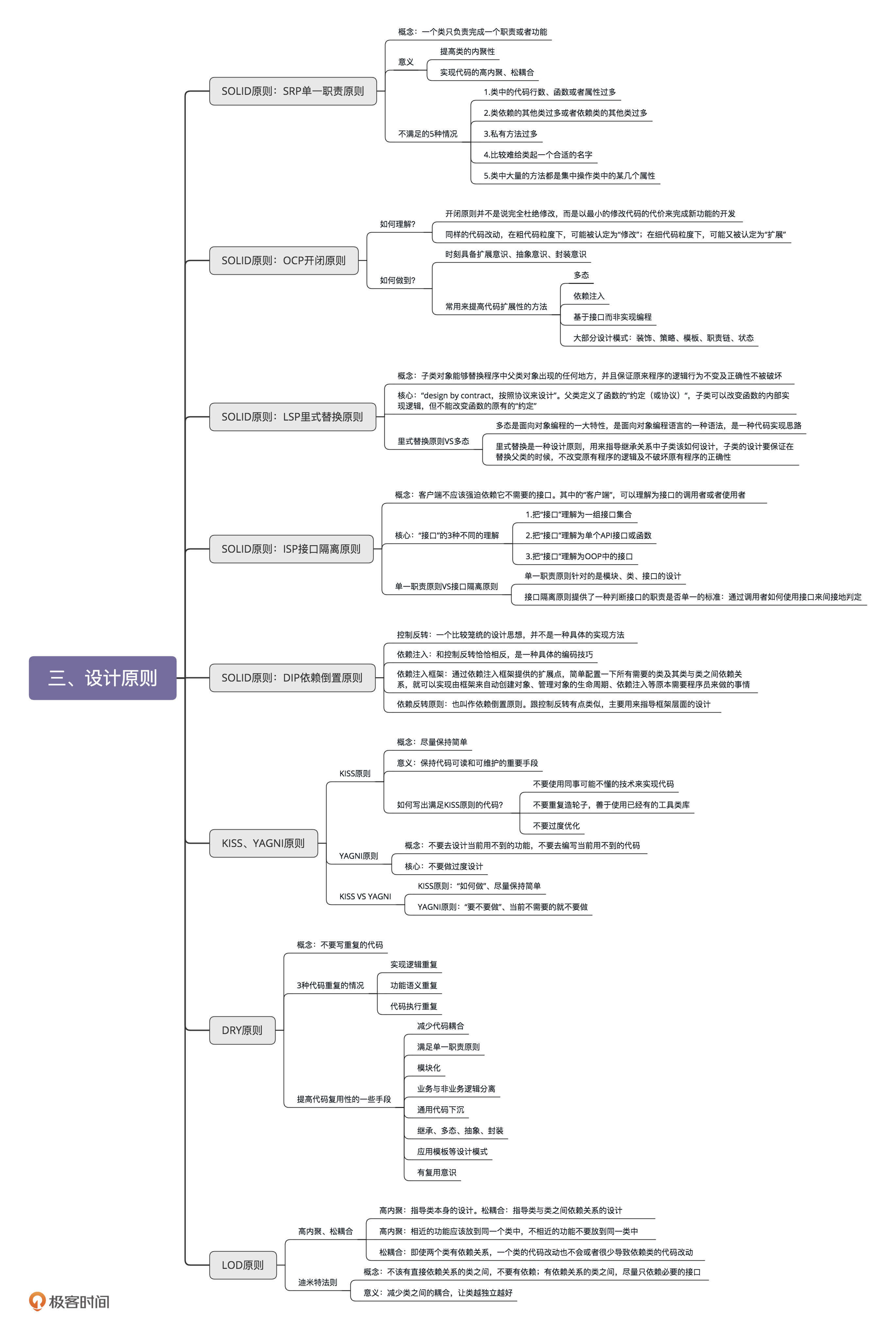
SOLID设计原则
2. 二十三种设计模式
2.1 设计模式之禅
2.2 设计模式UML,Demo
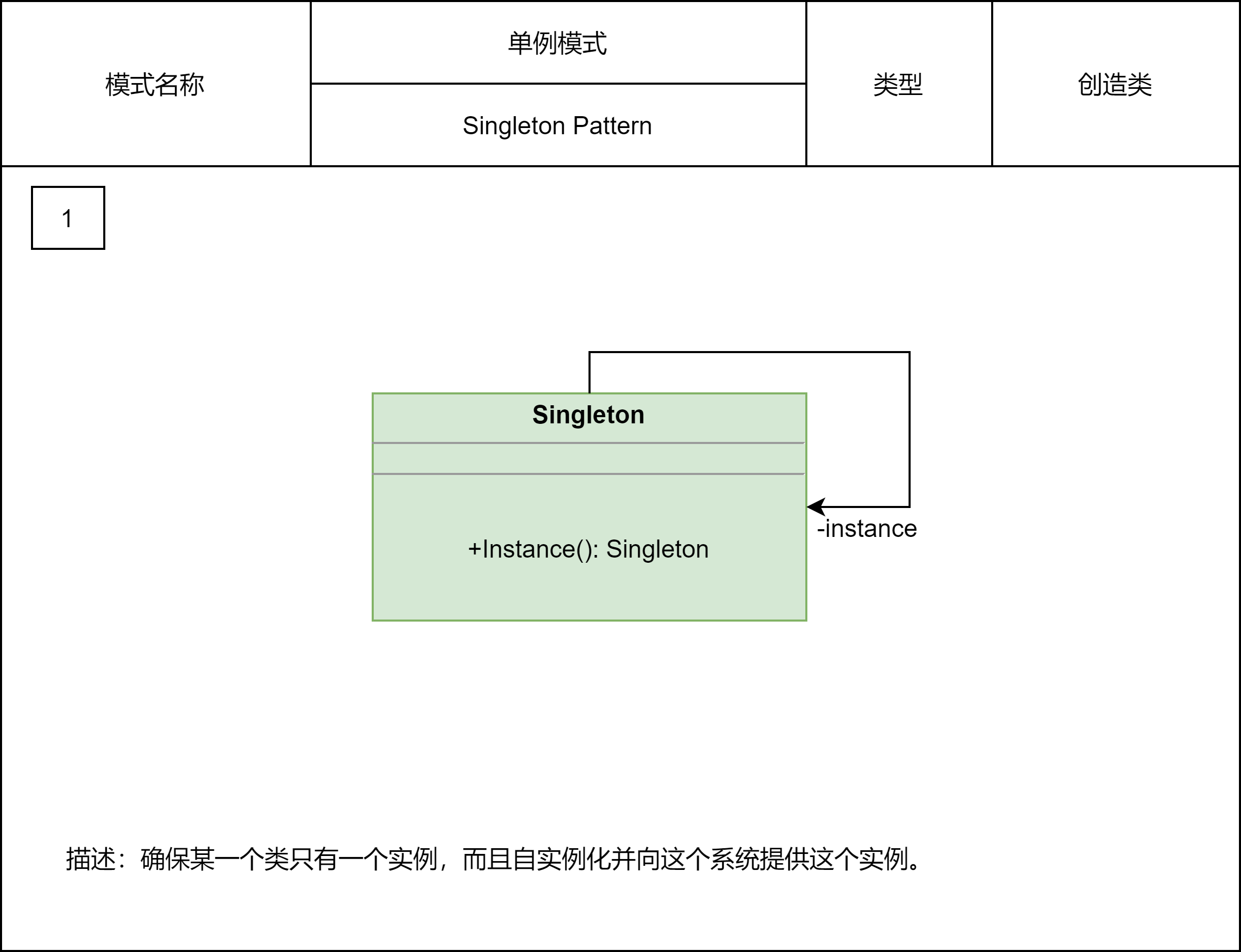
2.2.1 单例模式
单例模式用来创建全局唯一的对象。一个类只允许创建一个对象(或者叫实例),那这个类就是一个单例类,这种设计模式就叫作单例模式。单例有几种经典的实现方式,它们分别是:饿汉式、懒汉式、双重检测、静态内部类、枚举。尽管单例是一个很常用的设计模式,在实际的开发中,我们也确实经常用到它,但是,有些人认为单例是一种反模式(anti-pattern),并不推荐使用,主要的理由有以下几点:
- 单例对OOP特性的支持不友好
- 单例会隐藏类之间的依赖关系
- 单例对代码的扩展性不友好
- 单例对代码的可测试性不友好
- 单例不支持有参数的构造函数
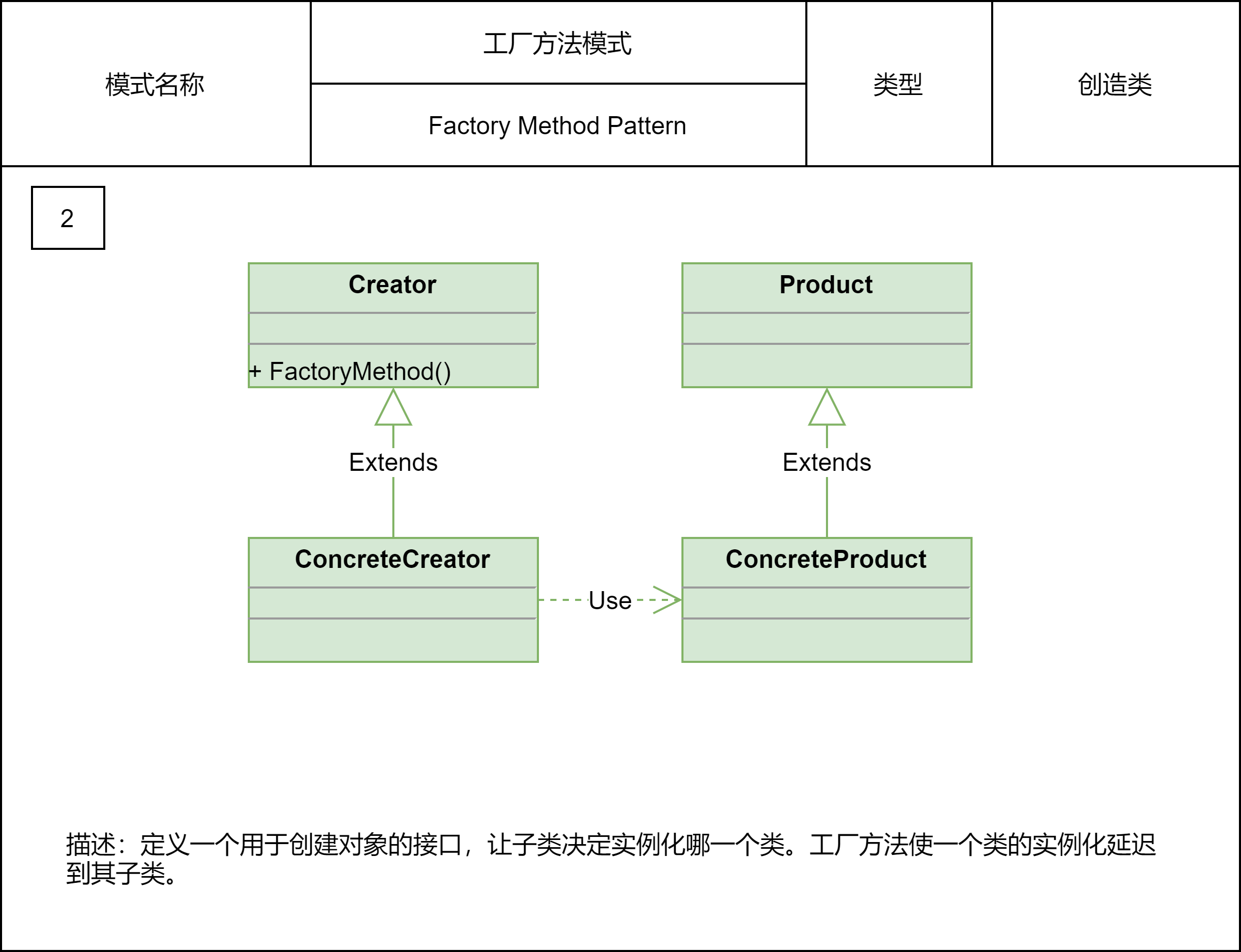
2.2.2 工厂方法模式
工厂模式包括简单工厂、工厂方法、抽象工厂这3种细分模式。其中,简单工厂和工厂方法比较常用。
工厂模式用来创建不同但是相关类型的对象(继承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。实际上,如果创建对象的逻辑并不复杂,直接通过new来创建对象就可以了,不需要使用工厂模式。当创建逻辑比较复杂,是一个“大工程”的时候,就考虑使用工厂模式,封装对象的创建过程,将对象的创建和使用相分离。
当每个对象的创建逻辑都比较简单的时候,推荐使用简单工厂模式,将多个对象的创建逻辑放到一个工厂类中。当每个对象的创建逻辑都比较复杂的时候,为了避免设计一个过于庞大的工厂类,推荐使用工厂方法模式,将创建逻辑拆分得更细,每个对象的创建逻辑独立到各自的工厂类中。
详细点说,工厂模式的作用有下面4个,这也是判断要不要使用工厂模式最本质的参考标准。
- 封装变化:创建逻辑有可能变化,封装成工厂类之后,创建逻辑的变更对调用者透明。
- 代码复用:创建代码抽离到独立的工厂类之后可以复用。
- 隔离复杂性:封装复杂的创建逻辑,调用者无需了解如何创建对象。
- 控制复杂度:将创建代码抽离出来,让原本的函数或类职责更单一,代码更简洁。
工厂模式一个非常经典的应用场景:依赖注入框架,比如Spring IOC、Google Guice,它用来集中创建、组装、管理对象,跟具体业务代码解耦,让程序员聚焦在业务代码的开发上。
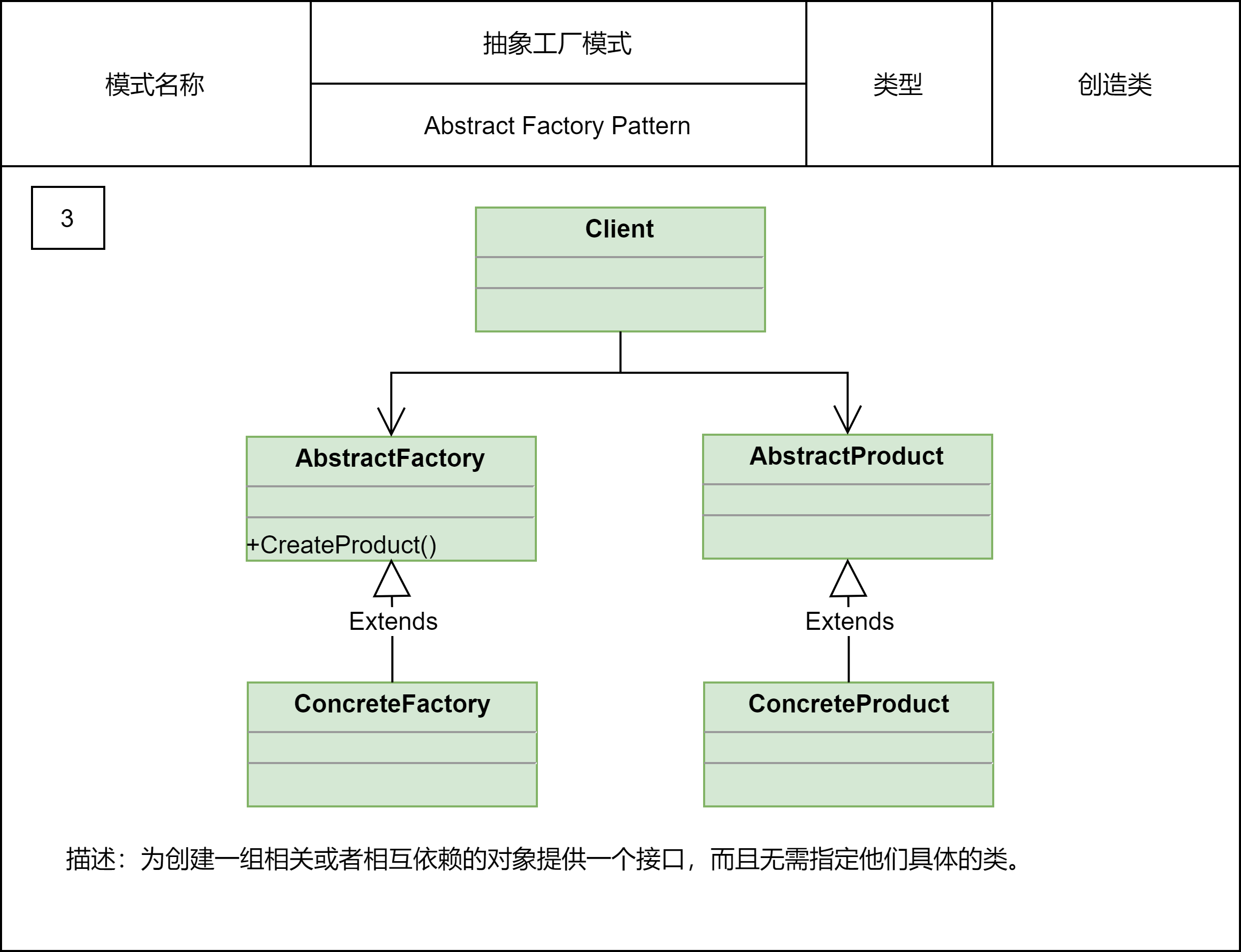
2.2.3 抽象工厂模式
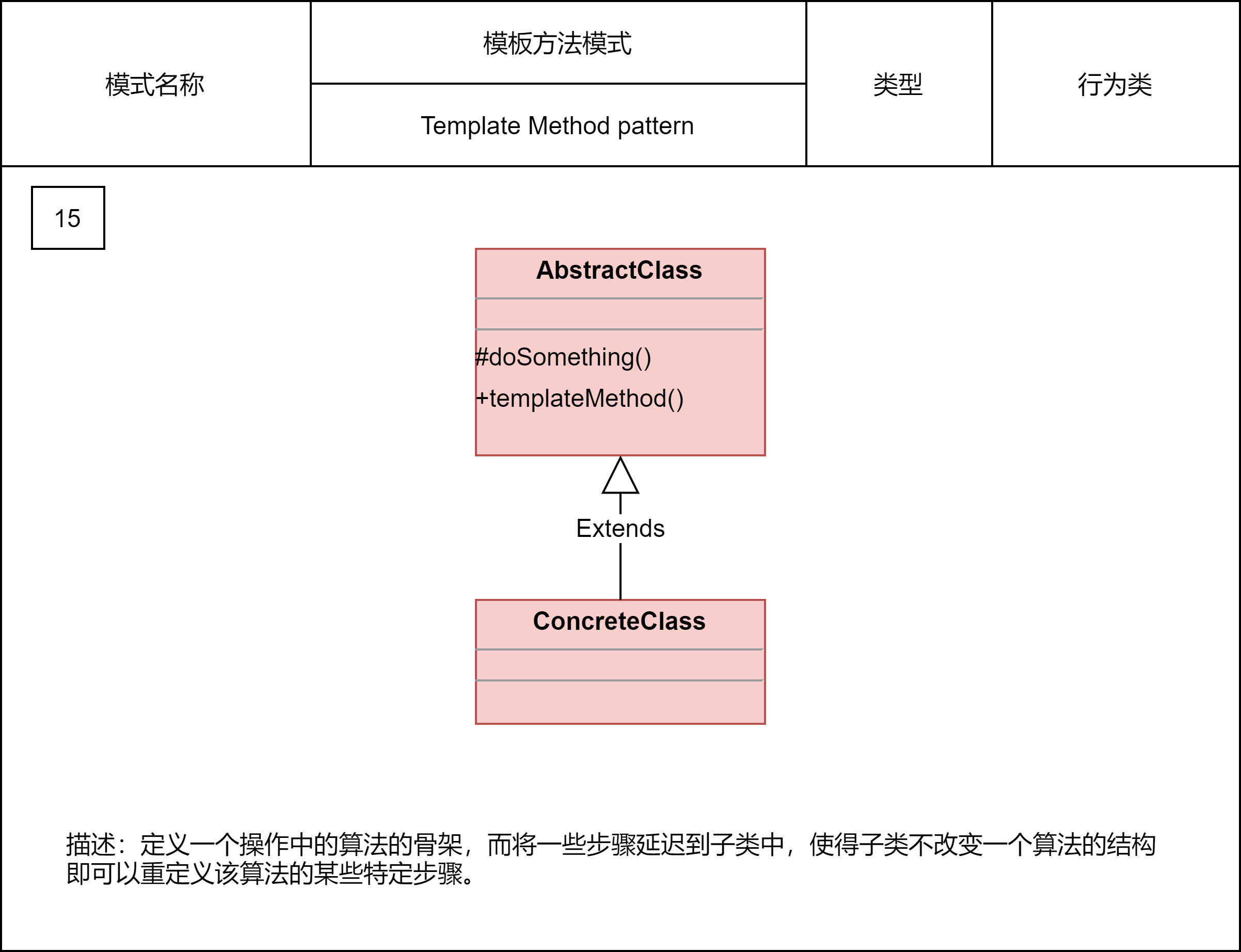
2.2.4 模板方法模式
模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。这里的“算法”,我们可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。模板模式有两大作用:复用和扩展。其中复用指的是,所有的子类可以复用父类中提供的模板方法的代码。扩展指的是,框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
2.2.5 建造者模式
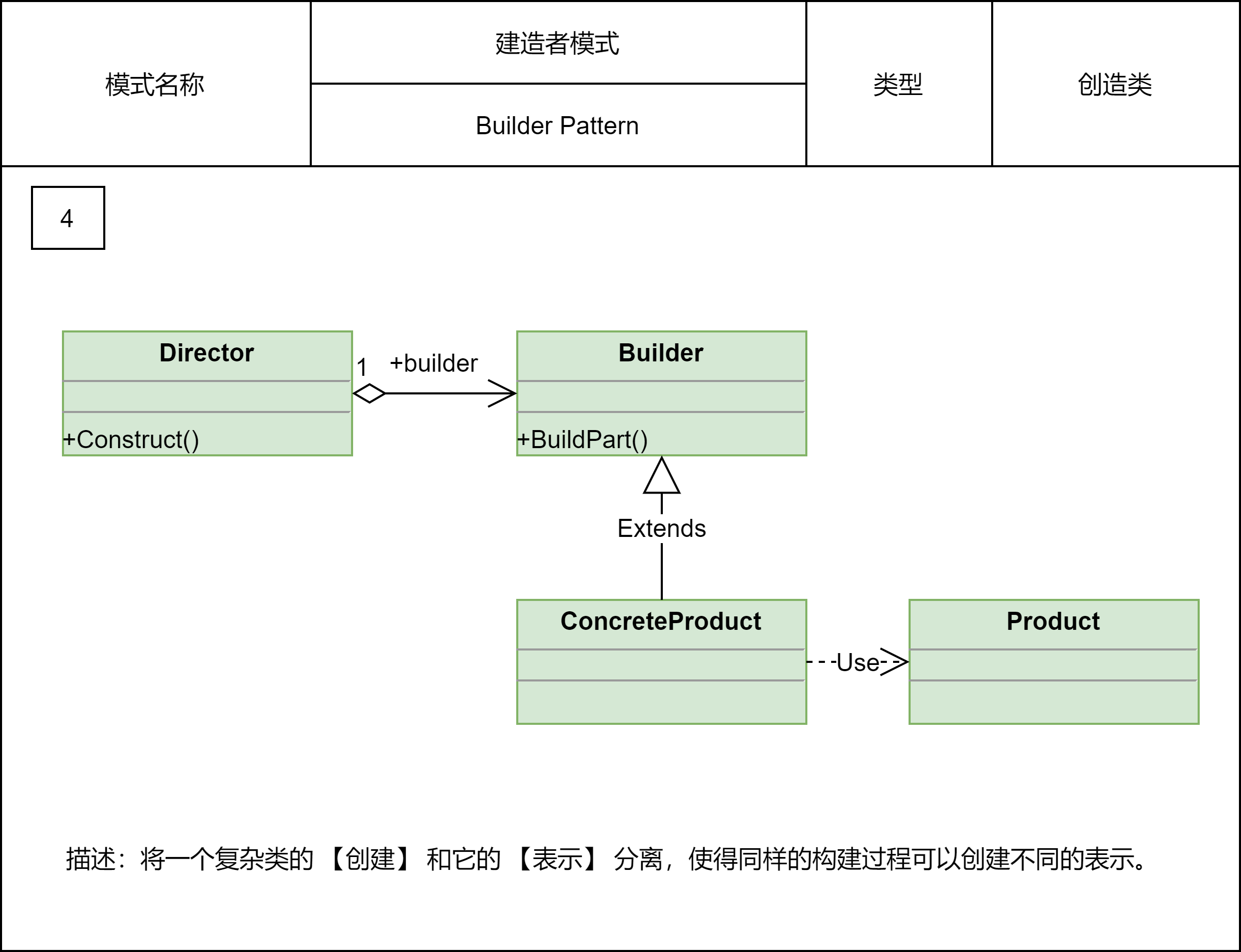
2.2.5.1 概念
不直接产生想要的对象,让客户端在builder对象上调用类似setter的方法,来设置每个相关的可选参数,最后客户端调用无参的build方法来生成通常不可变的对象。
2.2.5.2 Demo
1 | package com.mao.rong; |
在构建请求参数的时候,可以按照以上的方法设置具名的操作。当然想实现具名的请求参数构建,可以写为以下的方式:
1 |
|
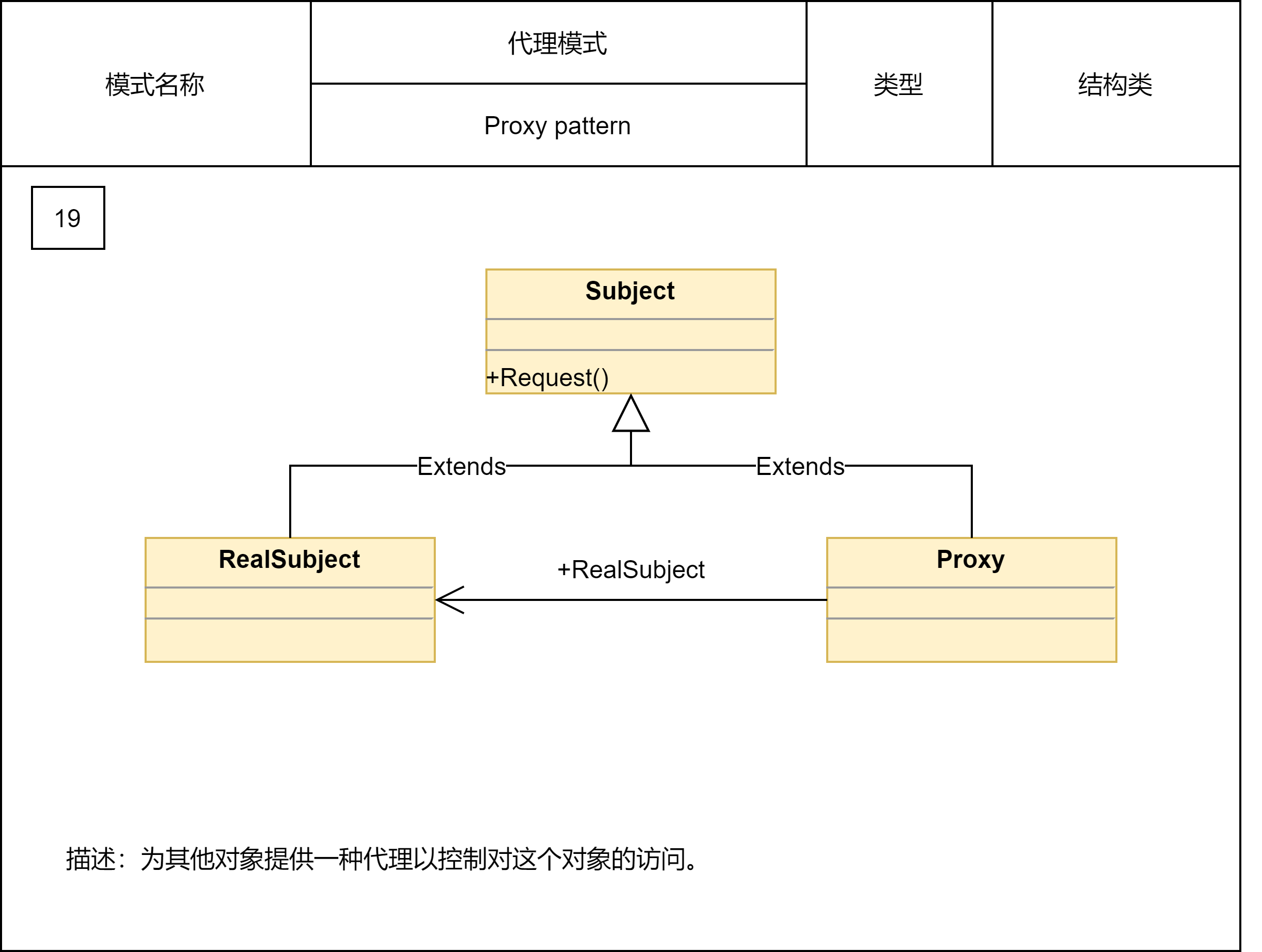
2.2.6 代理模式
代理模式在不改变原始类接口的条件下,为原始类定义一个代理类,主要目的是控制访问,而非加强功能,这是它跟装饰器模式最大的不同。一般情况下,我们让代理类和原始类实现同样的接口。但是,如果原始类并没有定义接口,并且原始类代码并不是我们开发维护的。在这种情况下,我们可以通过让代理类继承原始类的方法来实现代理模式。
- 静态代理需要针对每个类都创建一个代理类,并且每个代理类中的代码都有点像模板式的“重复”代码,增加了维护成本和开发成本。
- 对于静态代理存在的问题,我们可以通过动态代理来解决。我们不事先为每个原始类编写代理类,而是在运行的时候动态地创建原始类对应的代理类,然后在系统中用代理类替换掉原始类。
代理模式常用在业务系统中开发一些非功能性需求,比如:监控、统计、鉴权、限流、事务、幂等、日志。我们将这些附加功能与业务功能解耦,放到代理类统一处理,让程序员只需要关注业务方面的开发。除此之外,代理模式还可以用在RPC、缓存等应用场景中。
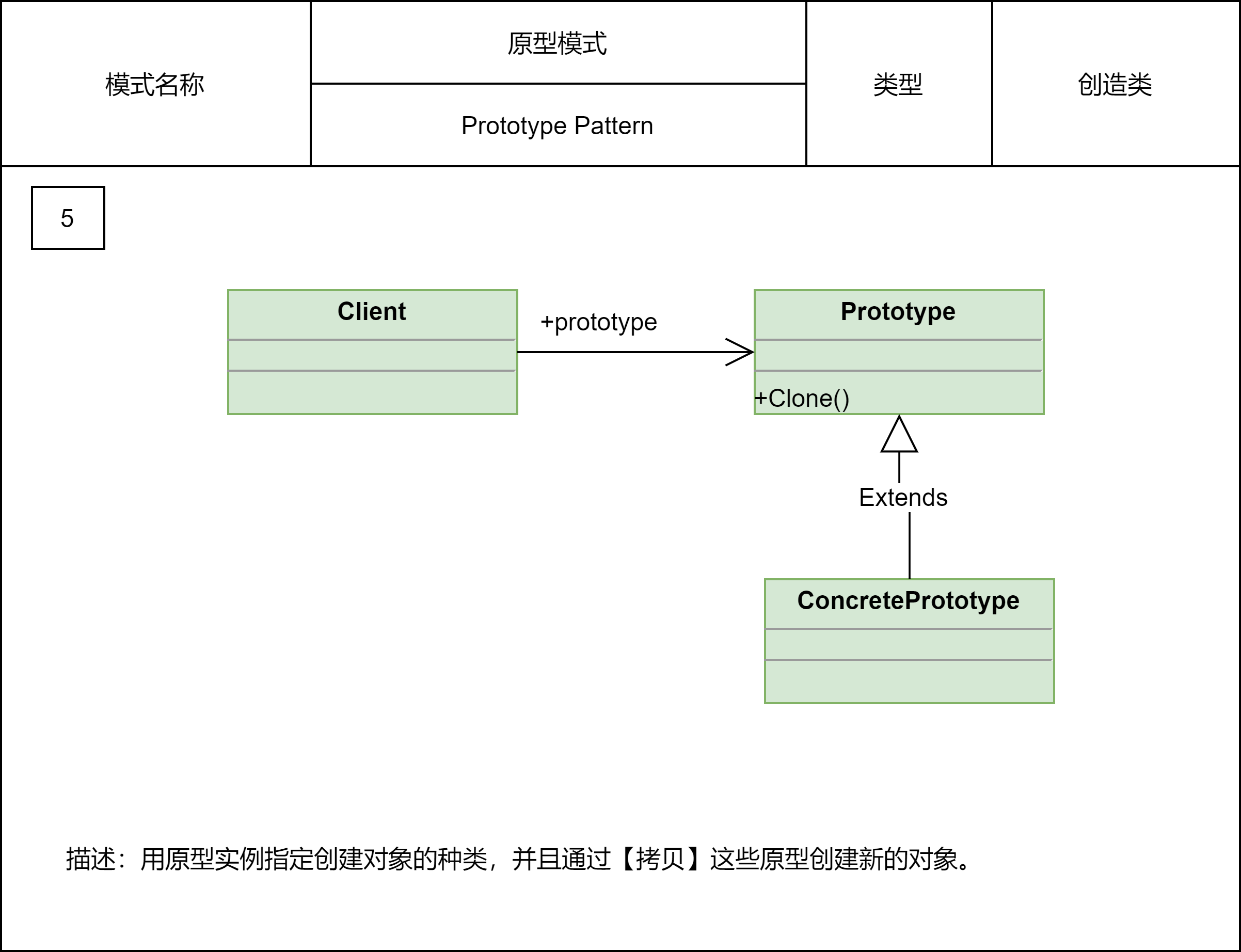
2.2.7 原型模式
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式,来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型模式。
原型模式有两种实现方法,深拷贝和浅拷贝。浅拷贝只会复制对象中基本数据类型数据和引用对象的内存地址,不会递归地复制引用对象,以及引用对象的引用对象。而深拷贝得到的是一份完完全全独立的对象。所以,深拷贝比起浅拷贝来说,更加耗时,更加耗内存空间。
如果要拷贝的对象是不可变对象,浅拷贝共享不可变对象是没问题的,但对于可变对象来说,浅拷贝得到的对象和原始对象会共享部分数据,就有可能出现数据被修改的风险,也就变得复杂多了。操作非常耗时的情况下,我们比较推荐使用浅拷贝,否则,没有充分的理由,不要为了一点点的性能提升而使用浅拷贝。
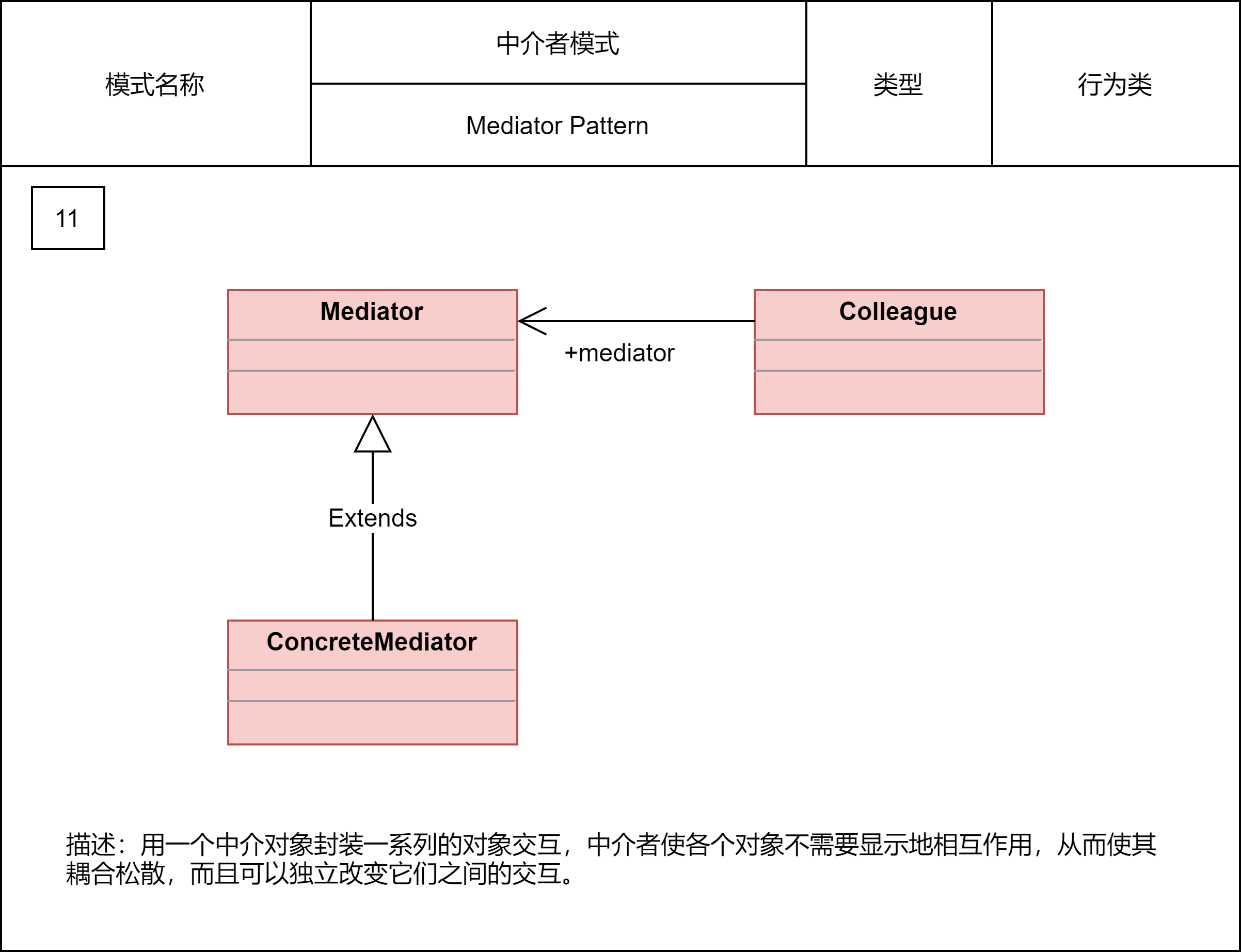
2.2.8 中介者模式
中介模式的设计思想跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系(或者说依赖关系)从多对多(网状关系)转换为一对多(星状关系)。原来一个对象要跟n个对象交互,现在只需要跟一个中介对象交互,从而最小化对象之间的交互关系,降低了代码的复杂度,提高了代码的可读性和可维护性。
观察者模式和中介模式都是为了实现参与者之间的解耦,简化交互关系。两者的不同在于应用场景上。在观察者模式的应用场景中,参与者之间的交互比较有条理,一般都是单向的,一个参与者只有一个身份,要么是观察者,要么是被观察者。而在中介模式的应用场景中,参与者之间的交互关系错综复杂,既可以是消息的发送者、也可以同时是消息的接收者。
2.2.9 命令模式
命令模式用到最核心的实现手段,就是将函数封装成对象。我们知道,在大部分编程语言中,函数是没法作为参数传递给其他函数的,也没法赋值给变量。借助命令模式,我们将函数封装成对象,这样就可以实现把函数像对象一样使用。
命令模式的主要作用和应用场景,是用来控制命令的执行,比如,异步、延迟、排队执行命令、撤销重做命令、存储命令、给命令记录日志等,这才是命令模式能发挥独一无二作用的地方。
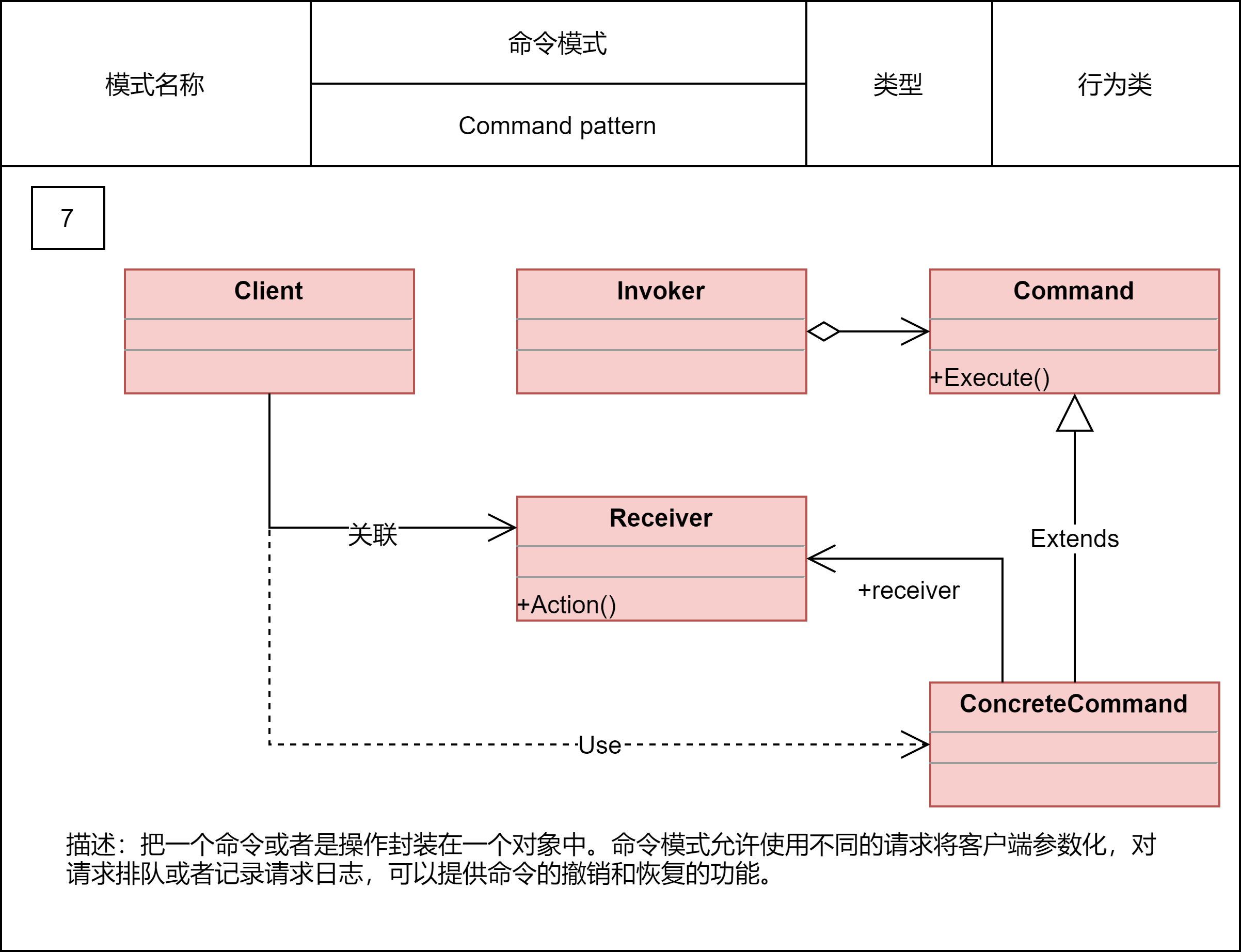
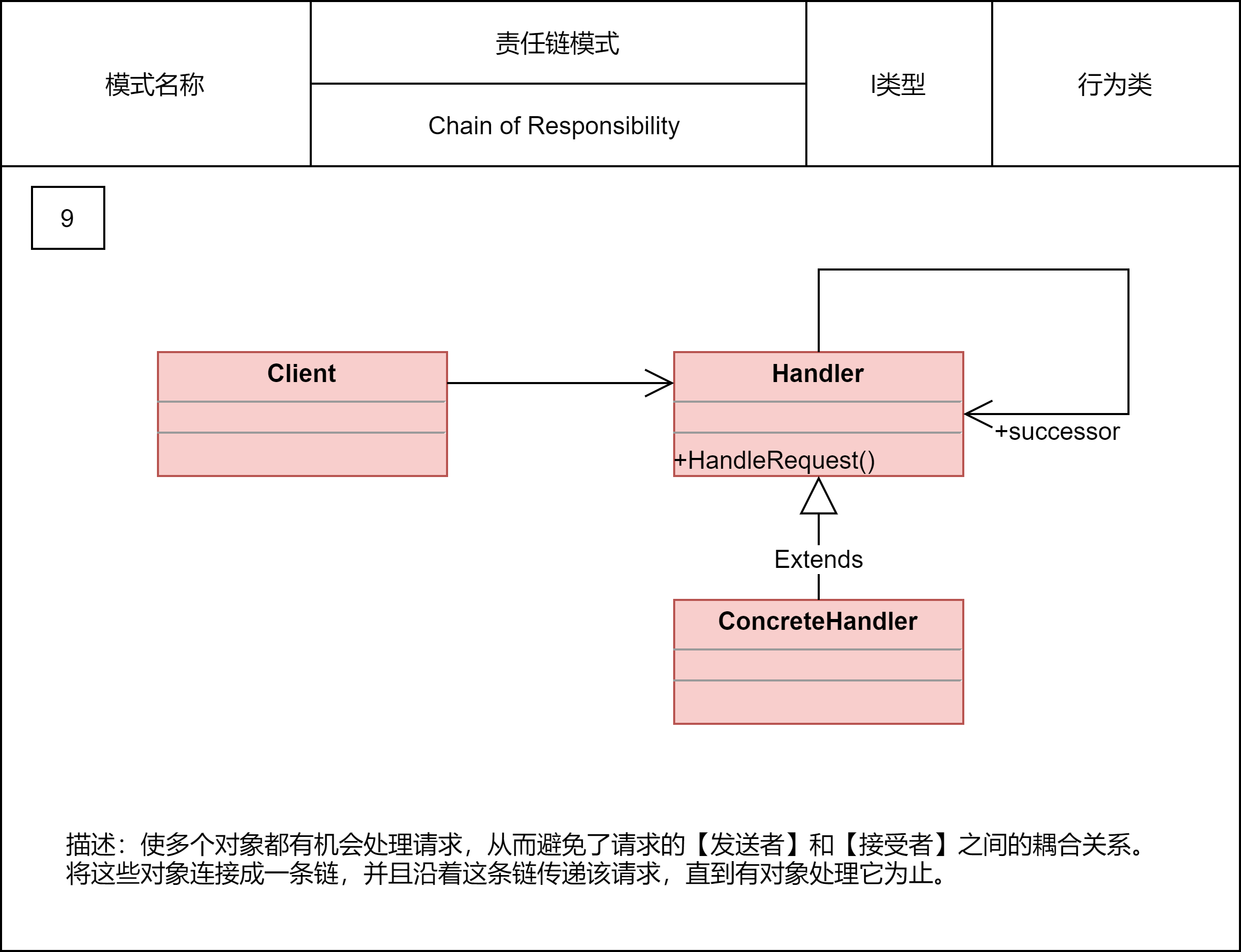
2.2.10 责任链模式
在职责链模式中,多个处理器依次处理同一个请求。一个请求先经过A处理器处理,然后再把请求传递给B处理器,B处理器处理完后再传递给C处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
在GoF的定义中,一旦某个处理器能处理这个请求,就不会继续将请求传递给后续的处理器了。当然,在实际的开发中,也存在对这个模式的变体,那就是请求不会中途终止传递,而是会被所有的处理器都处理一遍。
职责链模式常用在框架开发中,用来实现过滤器、拦截器功能,让框架的使用者在不需要修改框架源码的情况下,添加新的过滤、拦截功能。这也体现了之前讲到的对扩展开放、对修改关闭的设计原则。
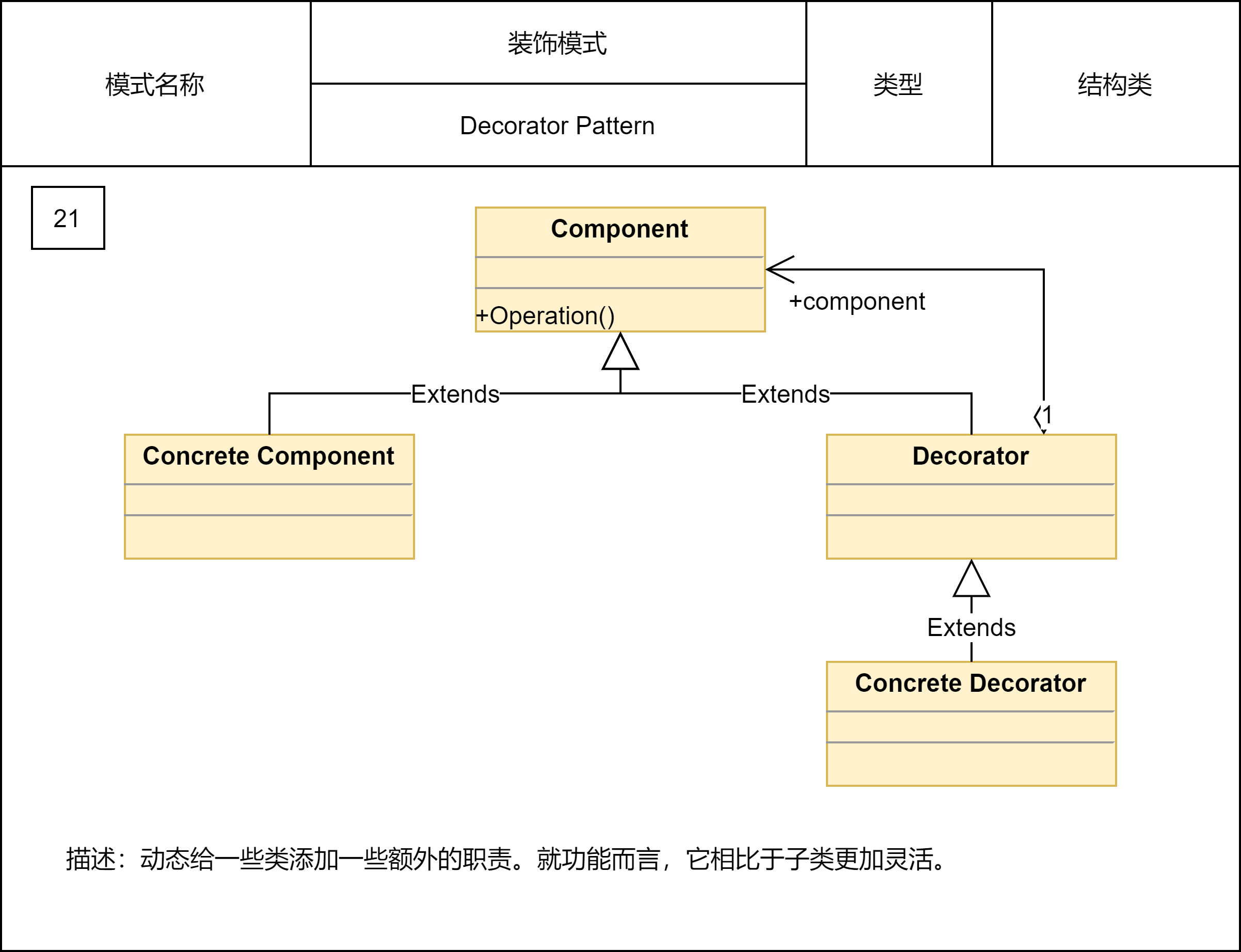
2.2.11 装饰模式
装饰器模式主要解决继承关系过于复杂的问题,通过组合来替代继承,给原始类添加增强功能。这也是判断是否该用装饰器模式的一个重要的依据。除此之外,装饰器模式还有一个特点,那就是可以对原始类嵌套使用多个装饰器。为了满足这样的需求,在设计的时候,装饰器类需要跟原始类继承相同的抽象类或者接口。
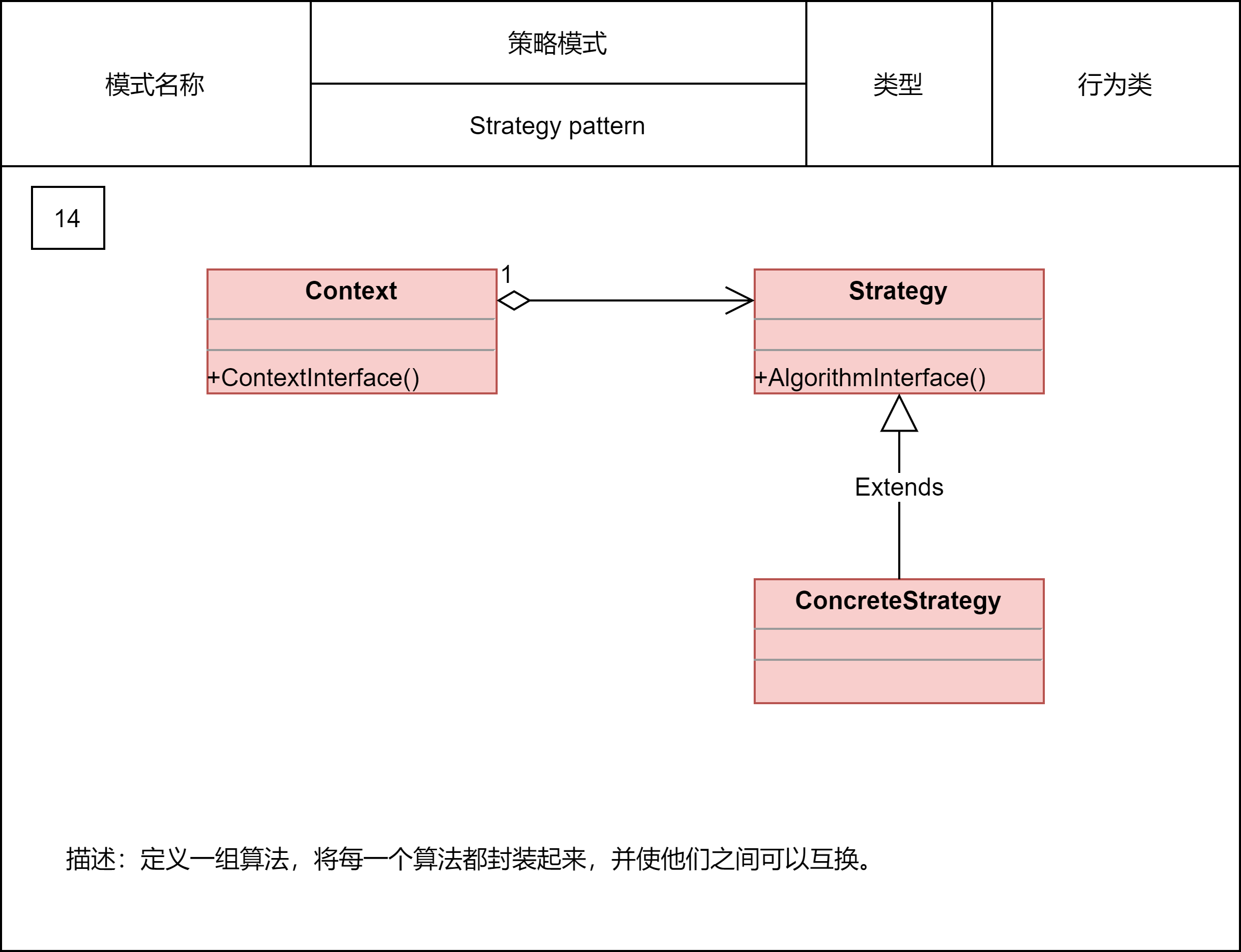
2.2.12 策略模式
策略模式定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。策略模式用来解耦策略的定义、创建、使用。实际上,一个完整的策略模式就是由这三个部分组成的。
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。策略的创建由工厂类来完成,封装策略创建的细节。策略模式包含一组策略可选,客户端代码选择使用哪个策略,有两种确定方法:编译时静态确定和运行时动态确定。其中,“运行时动态确定”才是策略模式最典型的应用场景。
在实际的项目开发中,策略模式也比较常用。最常见的应用场景是,利用它来避免冗长的if-else或switch分支判断。不过,它的作用还不止如此。它也可以像模板模式那样,提供框架的扩展点等等。实际上,策略模式主要的作用还是解耦策略的定义、创建和使用,控制代码的复杂度,让每个部分都不至于过于复杂、代码量过多。除此之外,对于复杂代码来说,策略模式还能让其满足开闭原则,添加新策略的时候,最小化、集中化代码改动,减少引入bug的风险。
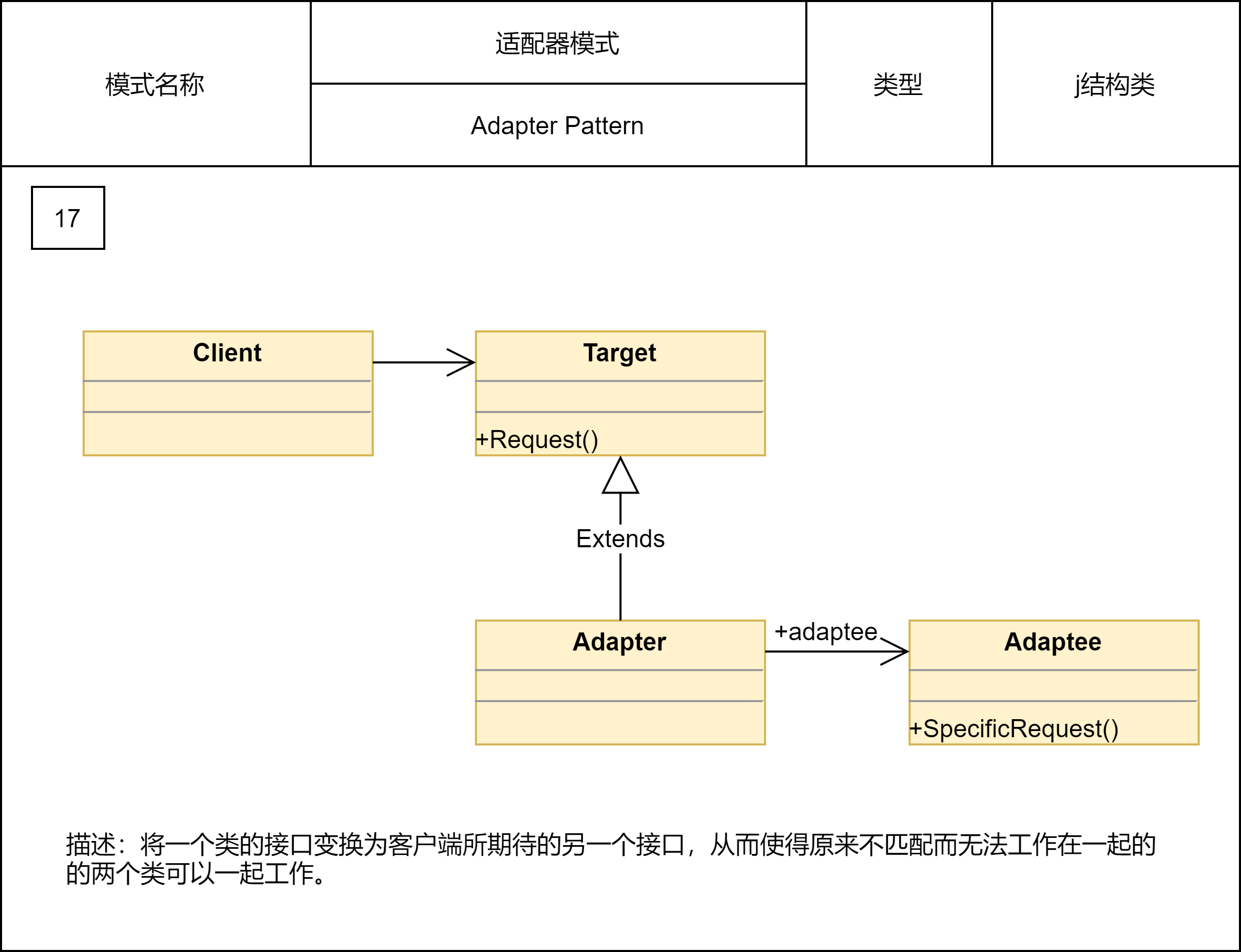
2.2.13 适配器模式
代理模式、装饰器模式提供的都是跟原始类相同的接口,而适配器提供跟原始类不同的接口。适配器模式是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
适配器模式是一种事后的补救策略,用来补救设计上的缺陷。应用这种模式算是“无奈之举”。如果在设计初期就能规避接口不兼容的问题,那这种模式就无用武之地了。在实际的开发中,什么情况下才会出现接口不兼容呢?总结下了下面这5种场景:
- 封装有缺陷的接口设计
- 统一多个类的接口设计
- 替换依赖的外部系统
- 兼容老版本接口
- 适配不同格式的数据
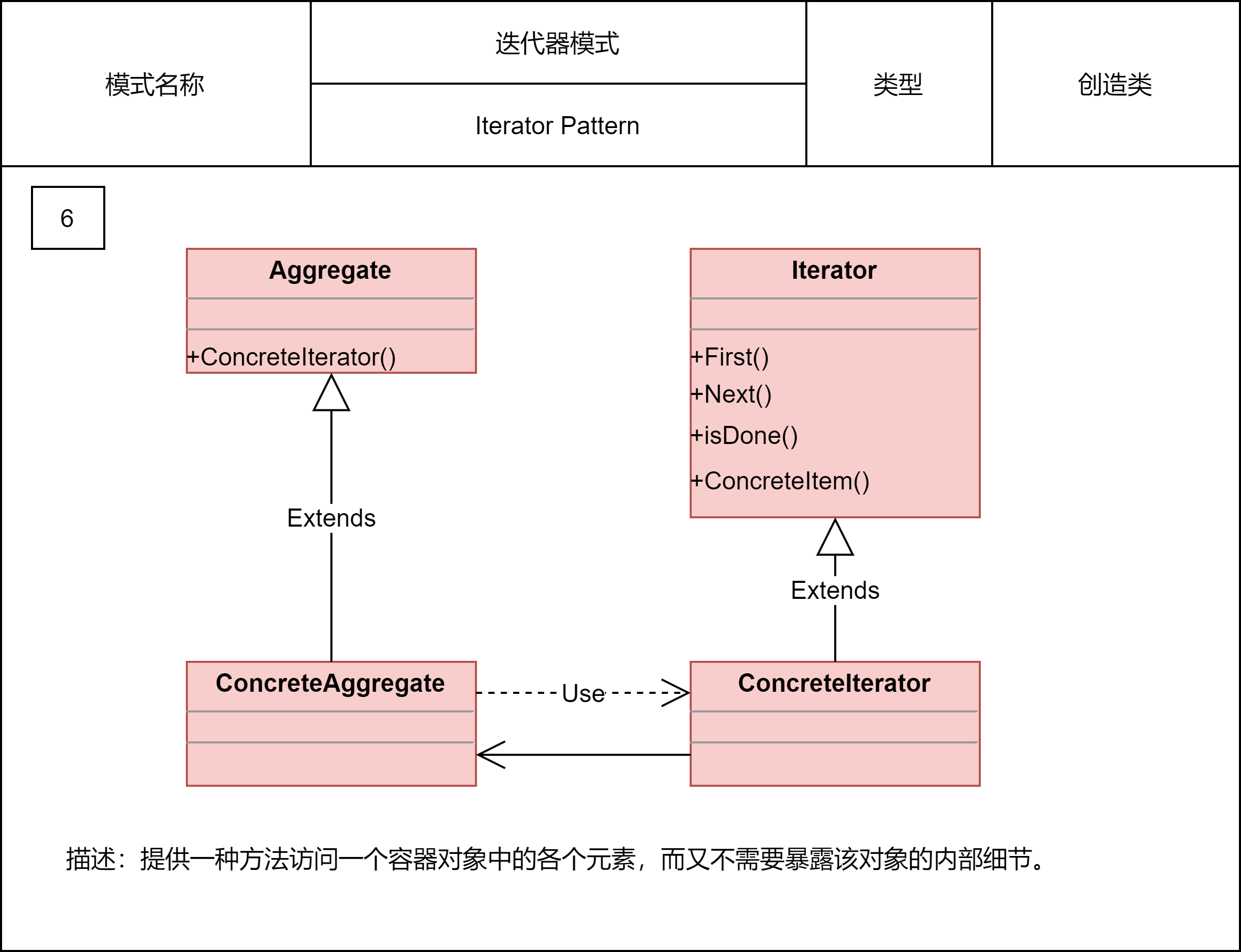
2.2.14 迭代器模式
在职责链模式中,多个处理器依次处理同一个请求。一个请求先经过A处理器处理,然后再把请求传递给B处理器,B处理器处理完后再传递给C处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
在GoF的定义中,一旦某个处理器能处理这个请求,就不会继续将请求传递给后续的处理器了。当然,在实际的开发中,也存在对这个模式的变体,那就是请求不会中途终止传递,而是会被所有的处理器都处理一遍。
职责链模式常用在框架开发中,用来实现过滤器、拦截器功能,让框架的使用者在不需要修改框架源码的情况下,添加新的过滤、拦截功能。这也体现了之前讲到的对扩展开放、对修改关闭的设计原则。
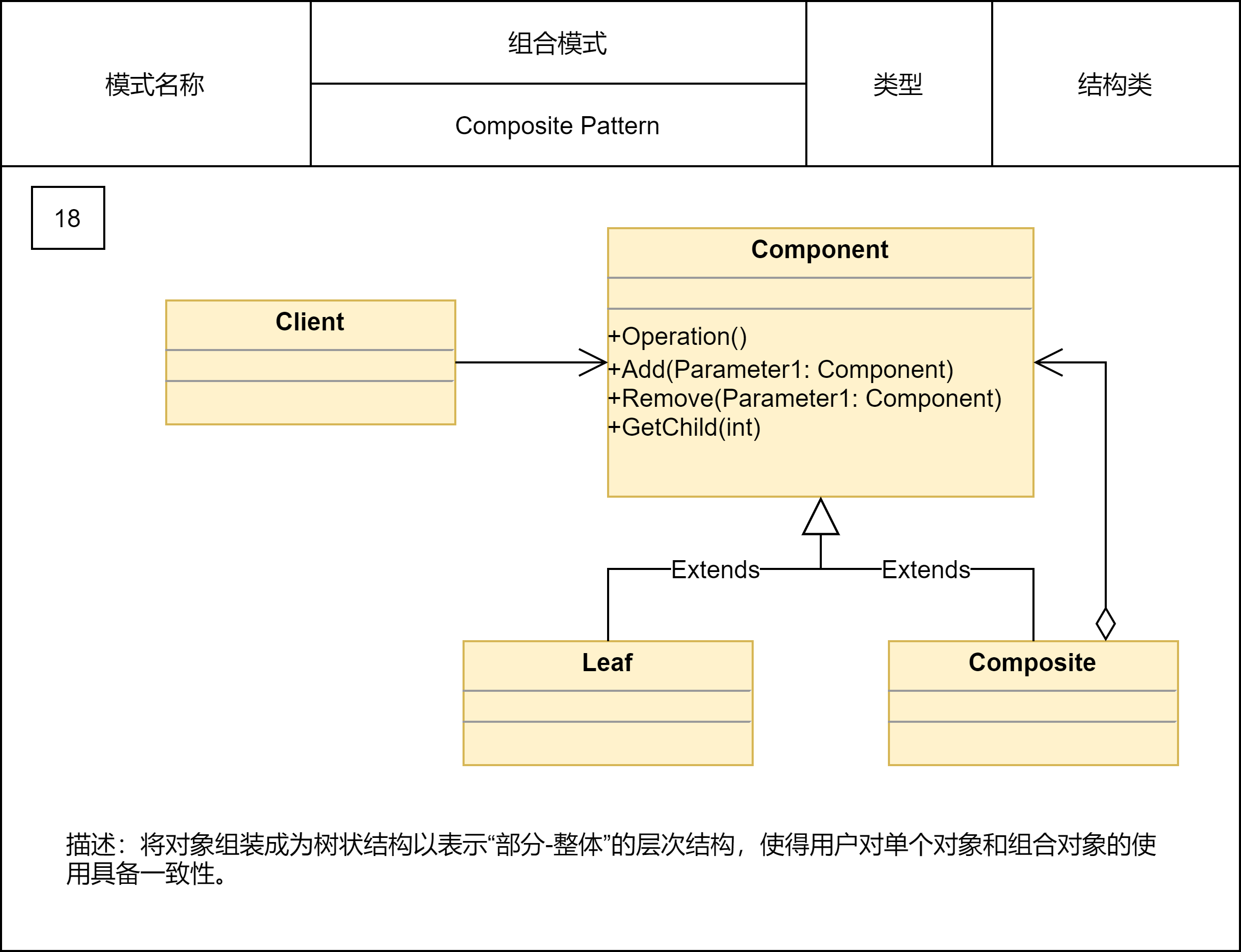
2.2.15 组合模式
用来处理树形结构数据。正因为其应用场景的特殊性,数据必须能表示成树形结构,这也导致了这种模式在实际的项目开发中并不那么常用。但是,一旦数据满足树形结构,应用这种模式就能发挥很大的作用,能让代码变得非常简洁。
组合模式的设计思路,与其说是一种设计模式,倒不如说是对业务场景的一种数据结构和算法的抽象。其中,数据可以表示成树这种数据结构,业务需求可以通过在树上的递归遍历算法来实现。组合模式,将一组对象组织成树形结构,将单个对象和组合对象都看作树中的节点,以统一处理逻辑,并且它利用树形结构的特点,递归地处理每个子树,依次简化代码实现。
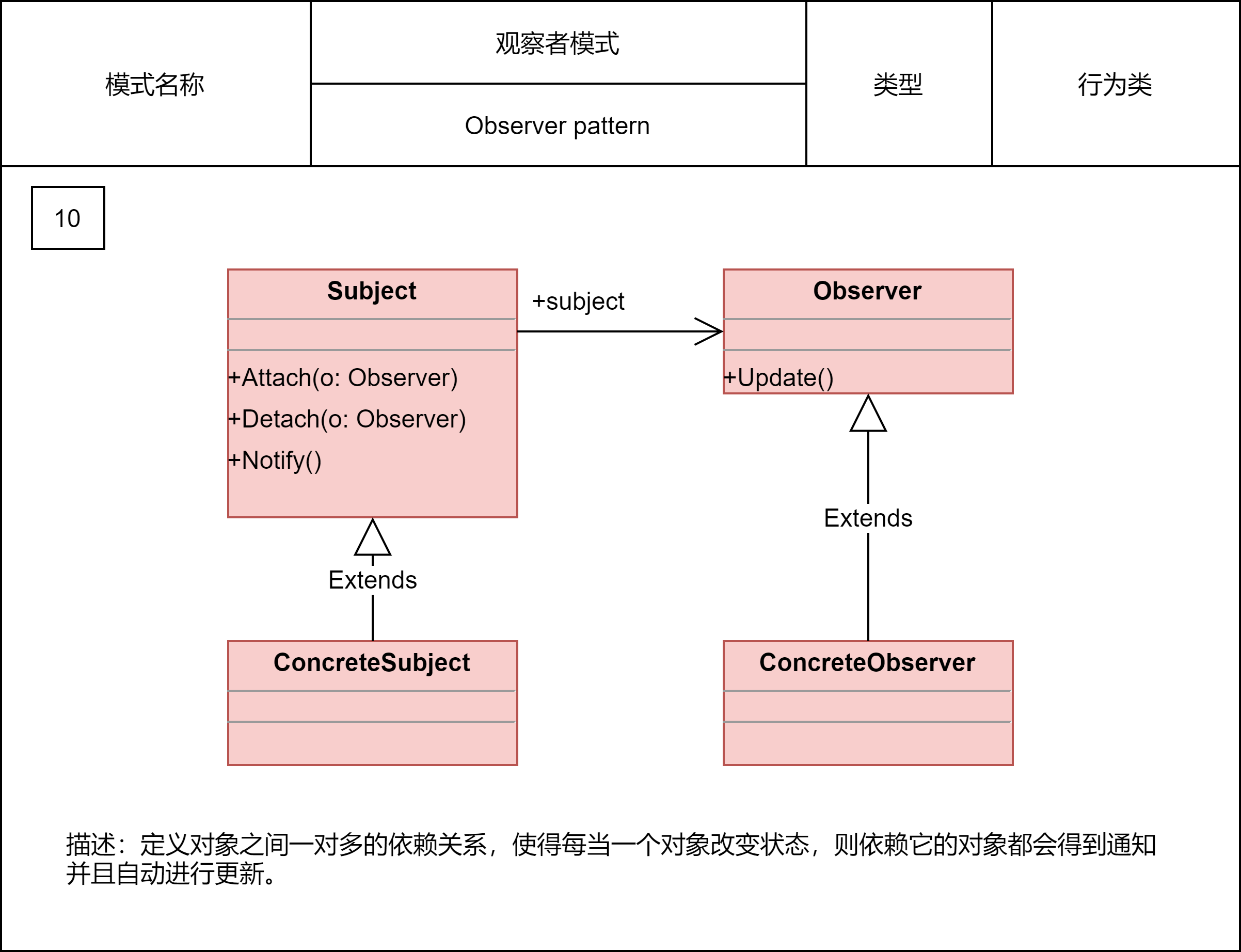
2.2.16 观察者模式
观察者模式将观察者和被观察者代码解耦。观察者模式的应用场景非常广泛,小到代码层面的解耦,大到架构层面的系统解耦,再或者一些产品的设计思路,都有这种模式的影子,比如,邮件订阅、RSS Feeds,本质上都是观察者模式。
不同的应用场景和需求下,这个模式也有截然不同的实现方式:有同步阻塞的实现方式,也有异步非阻塞的实现方式;有进程内的实现方式,也有跨进程的实现方式。同步阻塞是最经典的实现方式,主要是为了代码解耦;异步非阻塞除了能实现代码解耦之外,还能提高代码的执行效率;进程间的观察者模式解耦更加彻底,一般是基于消息队列来实现,用来实现不同进程间的被观察者和观察者之间的交互。
框架的作用有隐藏实现细节,降低开发难度,实现代码复用,解耦业务与非业务代码,让程序员聚焦业务开发。针对异步非阻塞观察者模式,我们也可以将它抽象成EventBus框架来达到这样的效果。EventBus翻译为“事件总线”,它提供了实现观察者模式的骨架代码。我们可以基于此框架非常容易地在自己的业务场景中实现观察者模式,不需要从零开始开发。
2.2.16.2 Demo
2.2.16.2.1 SpringListener
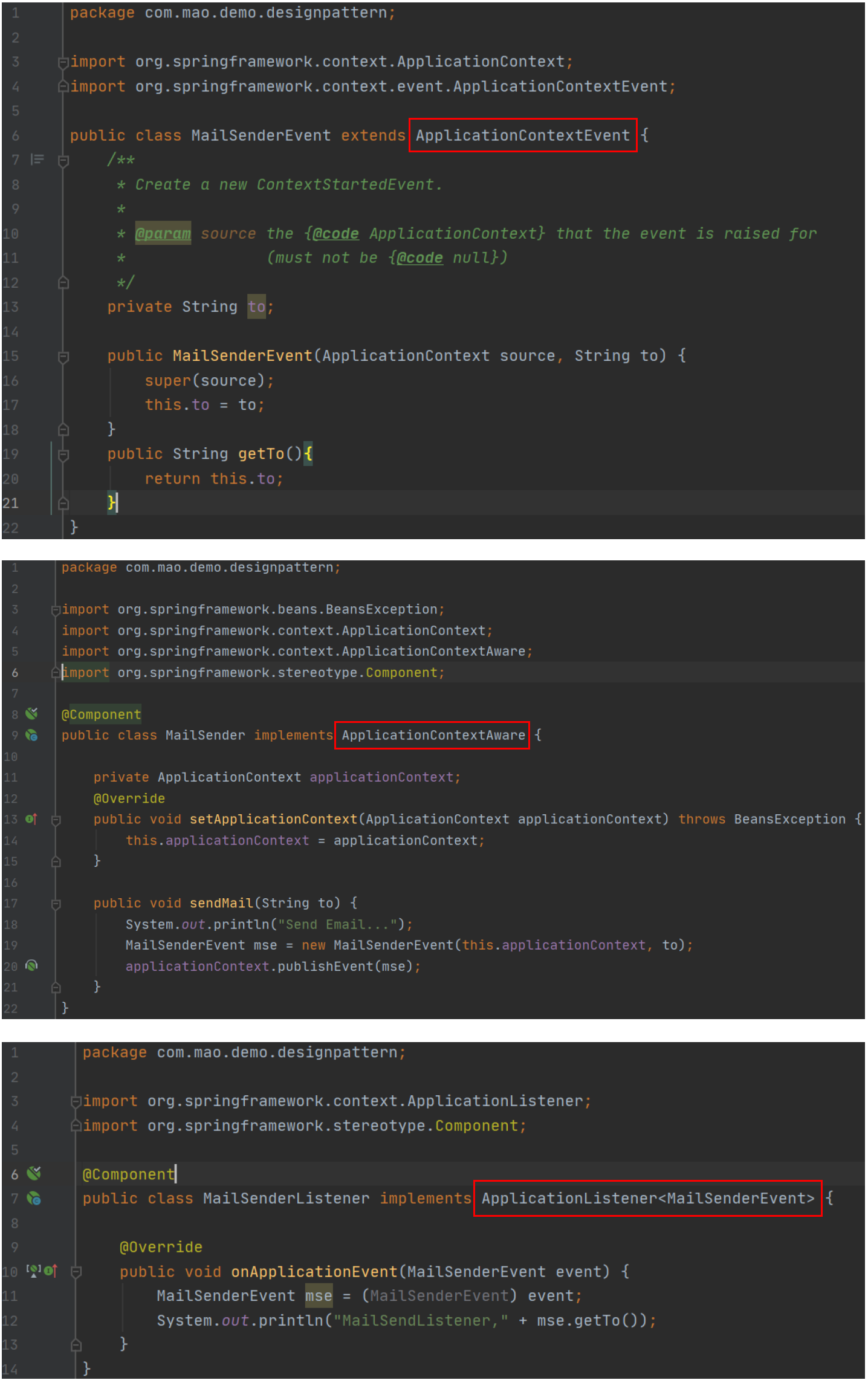
2.2.16.2.2 Guava EventBus
- 依赖
1 | <dependency> |
- Setup
1 | EventBus eventBus = new EventBus(); |
- Creating Listeners
1 | public class EventListener { |
- Registering Listeners
1 | EventListener listener = new EventListener(); |
- Unregistering Listeners
1 | eventBus.unregister(listener); |
- Posting Events
1 |
|
- Posting Custom Events
1 | public class CustomEvent { |
1 |
|
1 |
|
- Handling an Unsubscribed Event
1 |
|
Often, a given piece of code isn’t intrinsically an example of one pattern or another. This is why they’re called “patterns” (rather than, say, “implementation techniques”). A lot of software kinda looks like one pattern, but also resembles another — this is good. It’s best not to adhere to patterns for patterns’ sake, but to use them as a shared vocabulary for discussing architecture.
EventBus is one such tool. I wrote it with Observer-like situations in mind, but if you structure your application appropriately it can play a Mediator-like role.
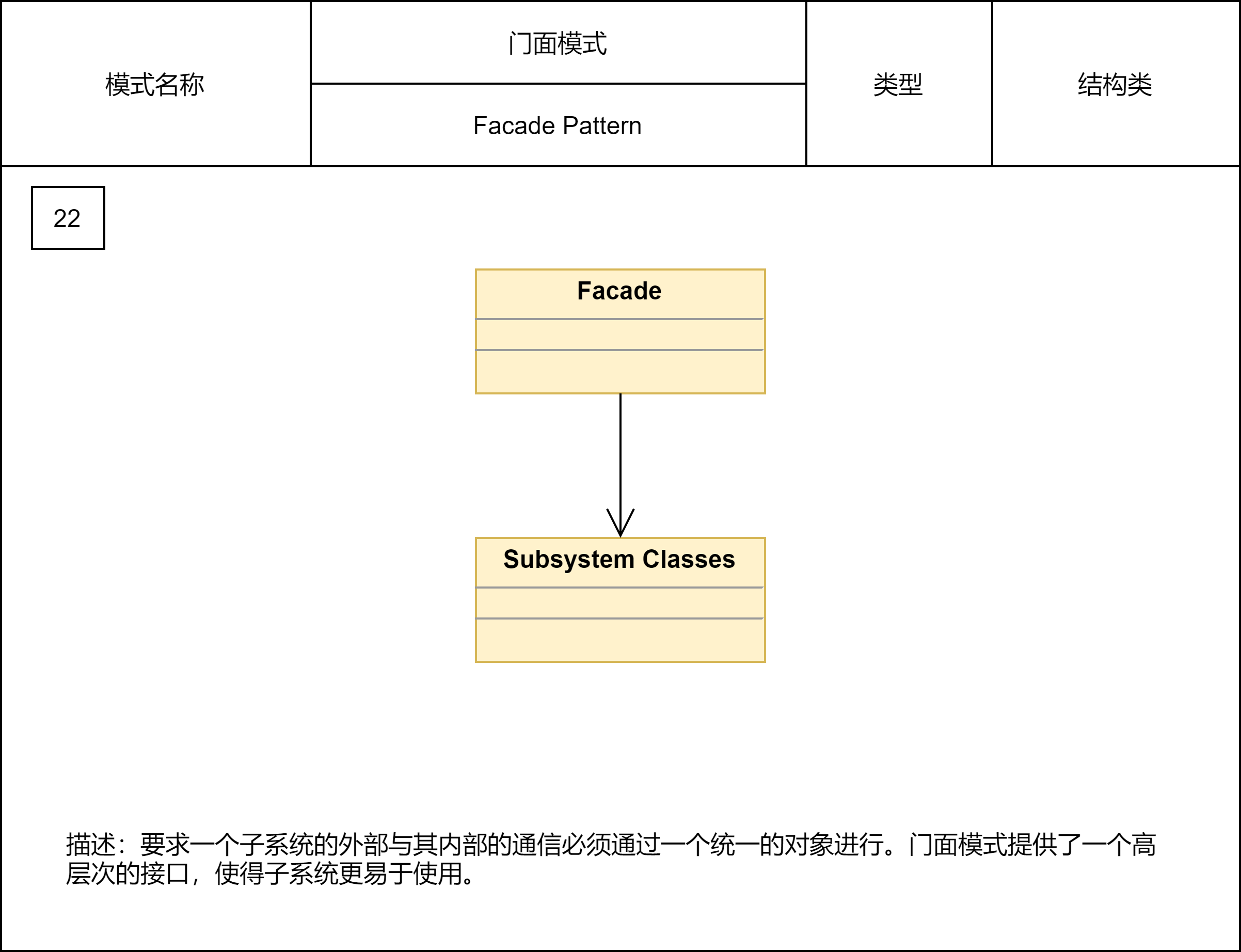
2.2.17 门面模式
门面模式原理、实现都非常简单,应用场景比较明确。它通过封装细粒度的接口,提供组合各个细粒度接口的高层次接口,来提高接口的易用性,或者解决性能、分布式事务等问题。
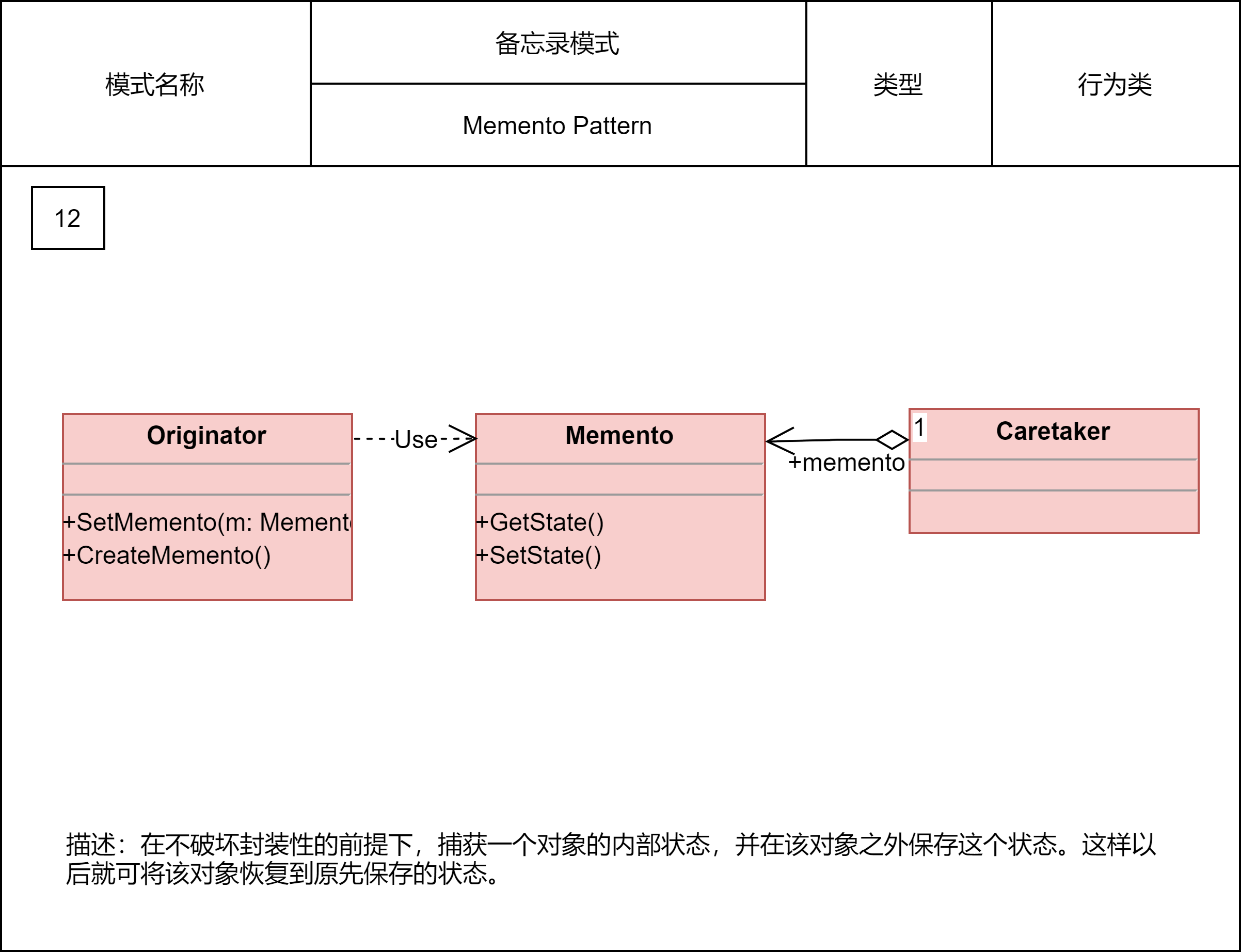
2.2.18 备忘录模式
备忘录模式也叫快照模式,具体来说,就是在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。这个模式的定义表达了两部分内容:一部分是,存储副本以便后期恢复;另一部分是,要在不违背封装原则的前提下,进行对象的备份和恢复。
备忘录模式的应用场景也比较明确和有限,主要用来防丢失、撤销、恢复等。它跟平时我们常说的“备份”很相似。两者的主要区别在于,备忘录模式更侧重于代码的设计和实现,备份更侧重架构设计或产品设计。
对于大对象的备份来说,备份占用的存储空间会比较大,备份和恢复的耗时会比较长。针对这个问题,不同的业务场景有不同的处理方式。比如,只备份必要的恢复信息,结合最新的数据来恢复;再比如,全量备份和增量备份相结合,低频全量备份,高频增量备份,两者结合来做恢复。
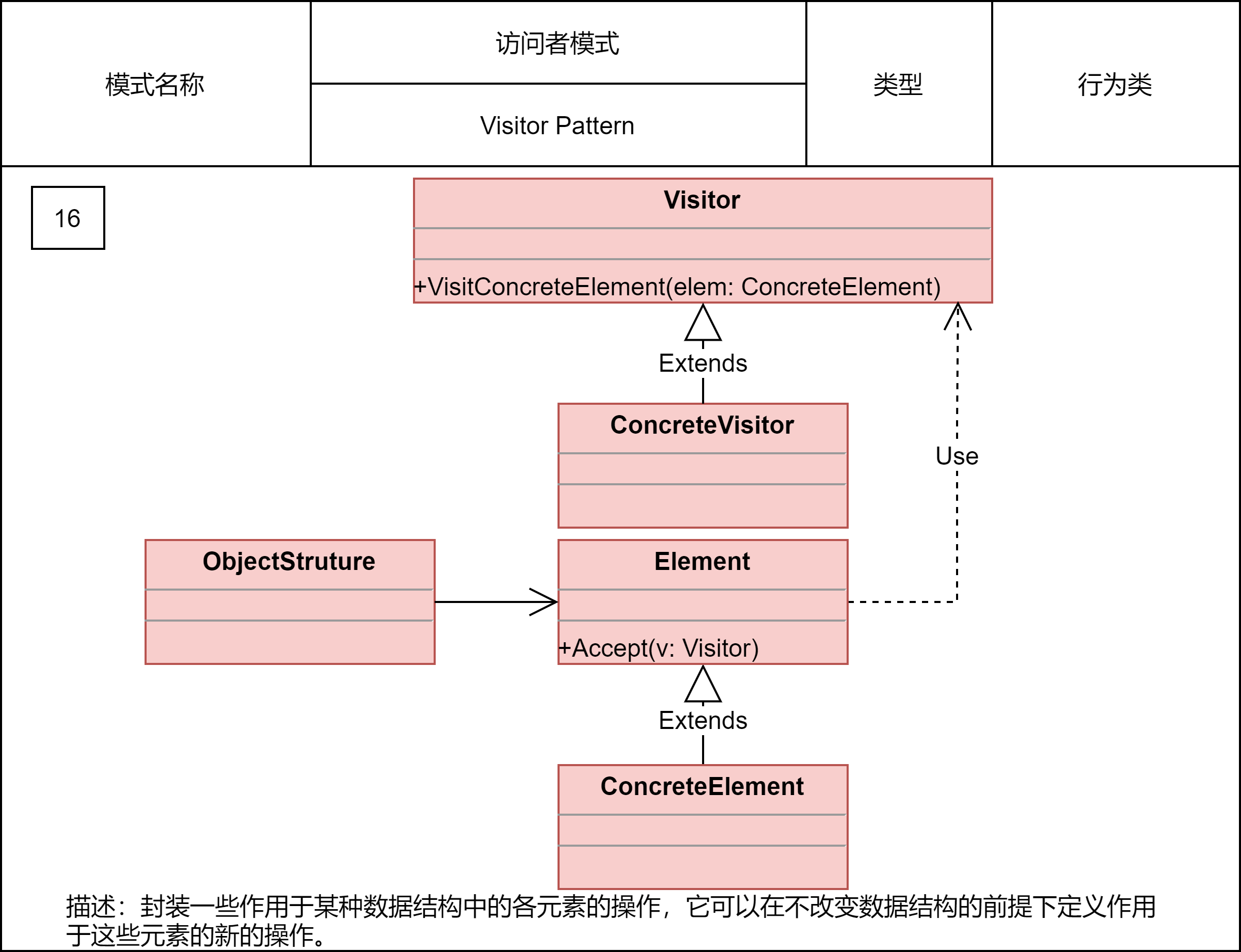
2.2.19 访问者模式
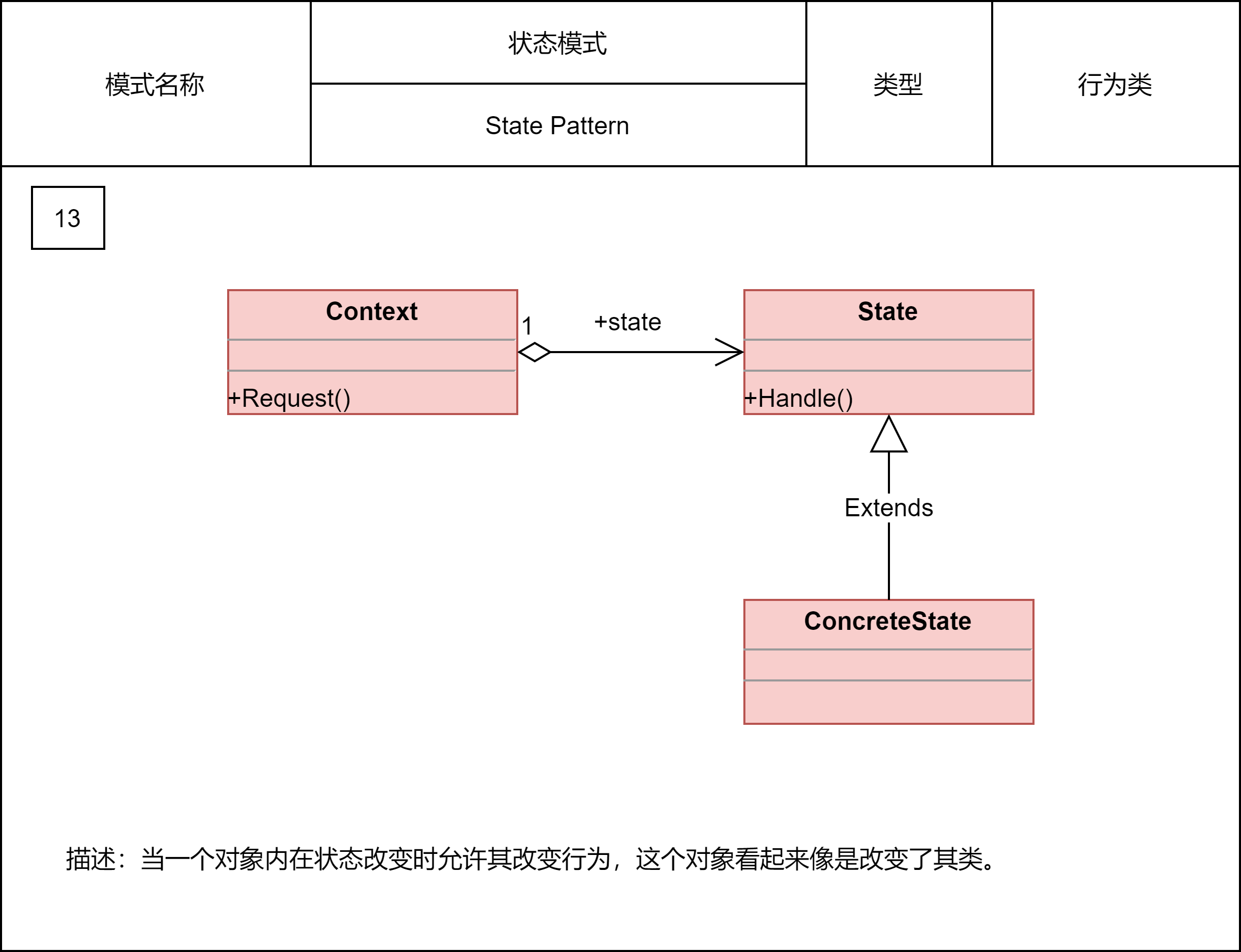
2.2.20 状态模式
状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。状态机又叫有限状态机,它由3个部分组成:状态、事件、动作。其中,事件也称为转移条件。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。针对状态机,总结了三种实现方式。
第一种实现方式叫分支逻辑法。利用if-else或者switch-case分支逻辑,参照状态转移图,将每一个状态转移原模原样地直译成代码。对于简单的状态机来说,这种实现方式最简单、最直接,是首选。
第二种实现方式叫查表法。对于状态很多、状态转移比较复杂的状态机来说,查表法比较合适。通过二维数组来表示状态转移图,能极大地提高代码的可读性和可维护性。
第三种实现方式就是利用状态模式。对于状态并不多、状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能比较复杂的状态机来说,我们首选这种实现方式。
2.2.21 解释器模式
解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。实际上,这里的“语言”不仅仅指我们平时说的中、英、日、法等各种语言。从广义上来讲,只要是能承载信息的载体,我们都可以称之为“语言”,比如,古代的结绳记事、盲文、哑语、摩斯密码等。
要想了解“语言”要表达的信息,我们就必须定义相应的语法规则。这样,书写者就可以根据语法规则来书写“句子”(专业点的叫法应该是“表达式”),阅读者根据语法规则来阅读“句子”,这样才能做到信息的正确传递。而我们要讲的解释器模式,其实就是用来实现根据语法规则解读“句子”的解释器。

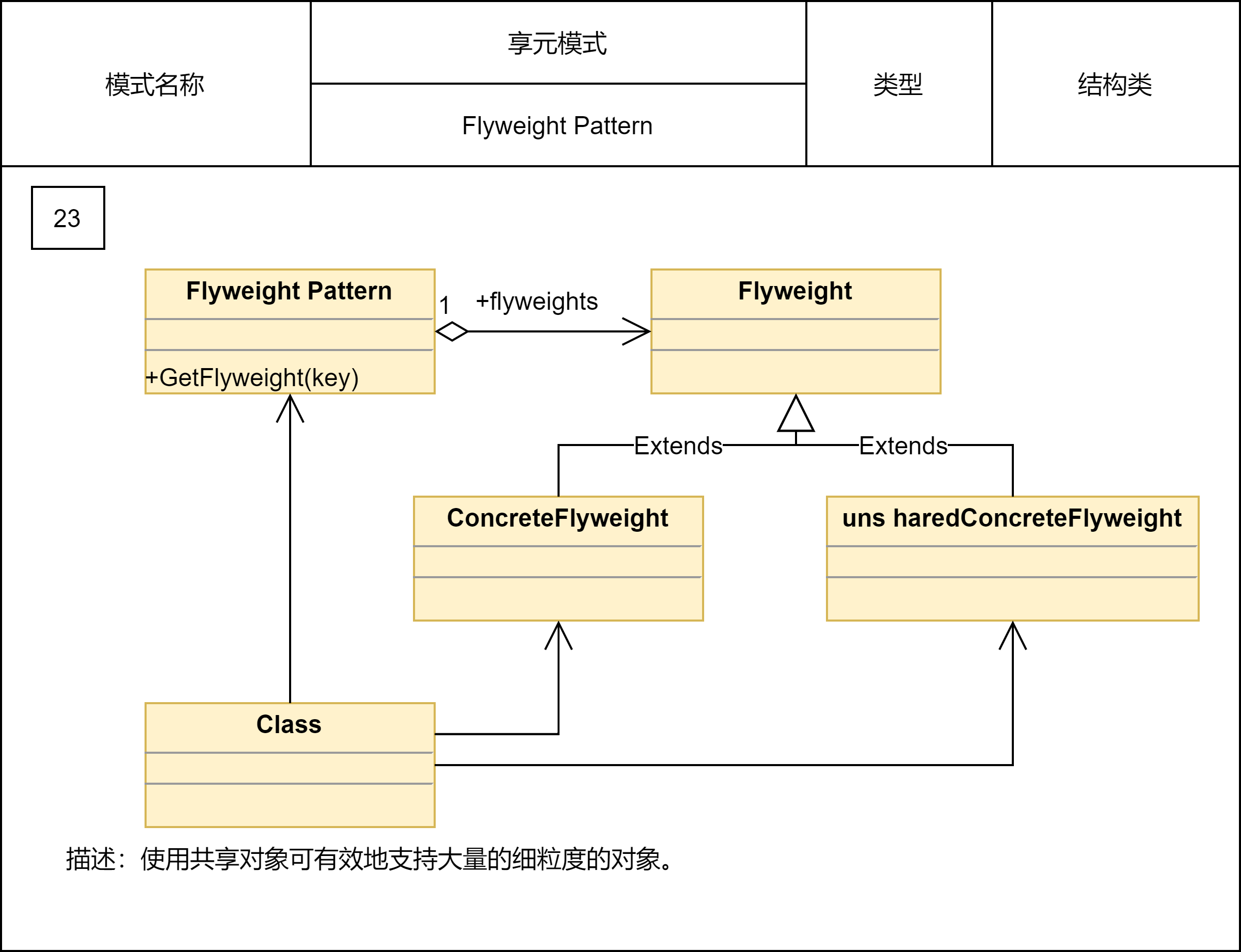
2.2.22 享元模式
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
具体来讲,当一个系统中存在大量重复对象的时候,我们就可以利用享元模式,将对象设计成享元,在内存中只保留一份实例,供多处代码引用,这样可以减少内存中对象的数量,以起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段),提取出来设计成享元,让这些大量相似对象引用这些享元。
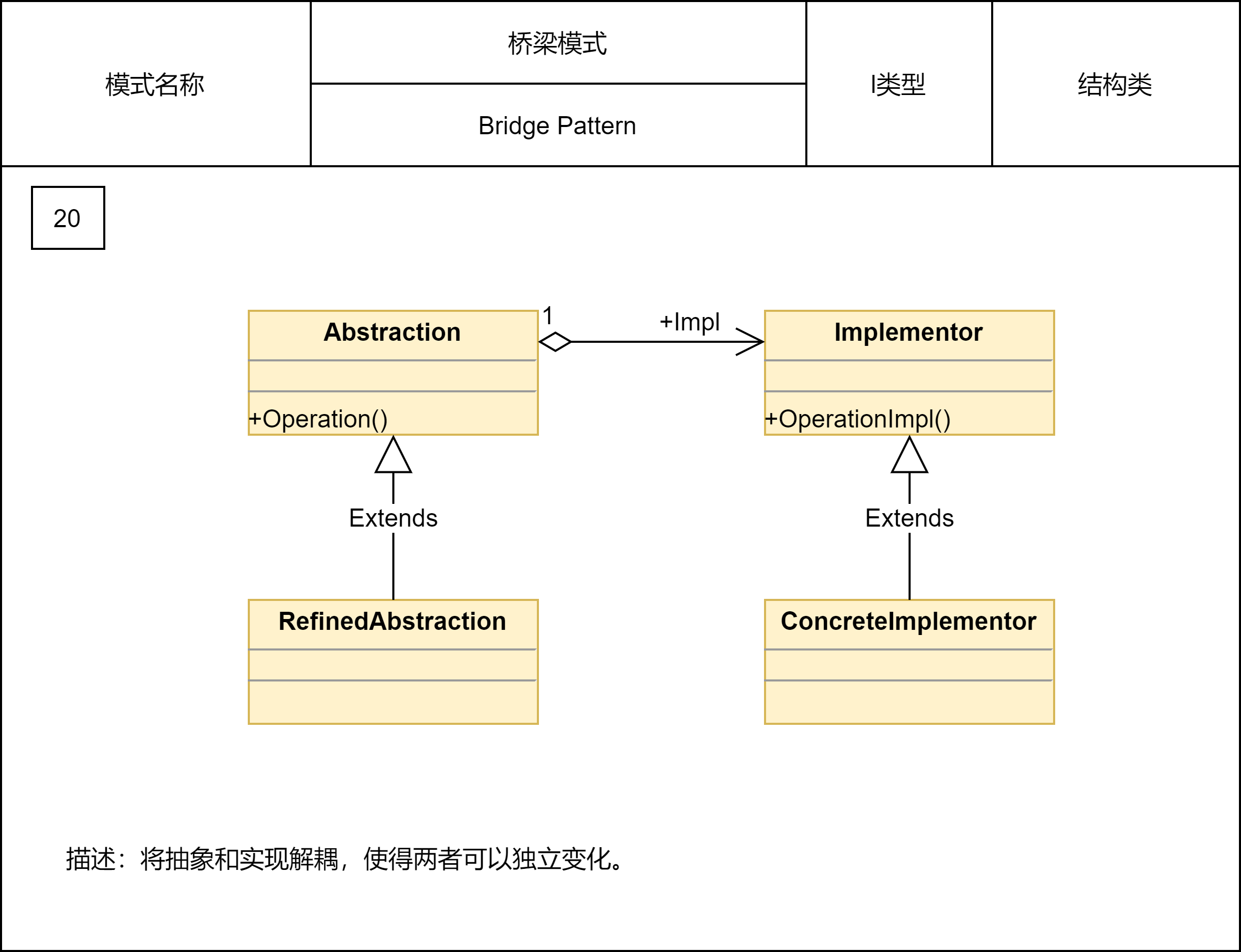
2.2.23 桥梁模式