Linux命令
收集linux相关命令,包含文件,网络,性能,编辑等.
文件相关
建立软链接,快速启动软件(不用修改环境变量)
1 | ss@ss:/usr/bin$ sudo ln -s /opt/pycharm/bin/pycharm.sh pycharm |
查看文件行数
1 | wc -l filename #就是查看文件里有多少行,wc -l *.csv ==>列出所有csv文件行数 |
查看文件的前/后 n 行
1 | head -n "文件名" |
用dd生成指定大小的文件
1 | #生成5GB数据 |
查看当前文件夹下文件的总个数
1 | ls -l | grep "^-" | wc -l |
重命名文件
1 | # 将文件名中包含A的文件名全部替换为B |
lsof
1 | # 1.列出所有打开的文件: |
批量解压(路径中含有空格)
1 | #/usr/bin env |
以上,为何问好就可以不用替换回空格呢?原因在于,在linux中问好号作为单个通配符使用是,可以匹配任何一个字符,也就是说不论是什么符号都可以匹配,所以不用替换回去!!!
检索(递归)所有文件
网络相关
连接远程服务器
1 | ssh tm@172.16.18.24 |
远程上传文件,下载文件命令
1 | # 下载 |
开通ssh服务
1 | # 查看是否开启了ssh服务是否安装,使用命令: |
ssh免密
1 | # 本地执行: |
tcpdump抓包
指定网卡,指定端口,指定host,写到test.pcap
1 | tcpdump -i ens7f0 port 10080 and host 192.168.126.3 -w test.pcap |
Ubuntu 镜像使用帮助
1 | # Ubuntu 的软件源配置文件是 /etc/apt/sources.list。将系统自带的该文件做个备份,将该文件替换为下面内容,即可使用 TUNA 的软件源镜像。 |
广播消息,给特定用户发消息
1 | # 特定用户 |
性能相关
后台运行相关
1 | fg、bg、jobs、&、ctrl+z |
杀掉所有的python进程(如:使用了多进程)
1 | ps -ef | grep python | grep -v grep | awk '{print $2}' | xargs kill -9 |
编辑相关
源码查看:主要使用vim快速查看函数的原型定义
1 | #(1)真对于系统函数,偶尔可以使用shift+K进行定位 |
替换命令
1 | :s/foo/bar/g Change each 'foo' to 'bar' in the current line. |
sed
- 命令格式
sed [-nefri] ‘command’ 文件名
选项
- -n
- -e(多条命令顺序执行,命令使用分号切割)
- -f
- -r
- -i(写入文件)
命令
- a(append新增)
- c(行替换)
- d(delete删除)
- i(insert前面插入)
- p(print打印)
- s(字符串的替换)
举例
cat user.txt
1
2
3
4
5ID Name Sex Age
1 zhang M 19
2 wang G 20
3 cheng M 10
4 huahua M 100在user.txt文件中;匹配带h的行 并且只显示1,3行
1
2
3
4cat user.txt | grep h |sed -n '1,3p'
1 zhang M 19
3 cheng M 10
4 huahua M 100删除最后一行记录
1
cat user.txt | grep h | sed '$d'
在user.txt中显示带h的行;并且从结果中删掉2,3行的记录;只看第一行记录
1
2cat user.txt | grep h |sed '2,3d'
1 zhang M 19在user.txt中查询出带h的行;并在第二行后面添加新的一行数据
1
cat user.txt | grep h |sed '2a5\thuang\tG\t40'
在第二行插入2行数据的签名插入新增的数据:
1
cat user.txt | grep h |sed '2i hello\nword'
把第二行数据;用命令c替换成 10 wanghua N 90
1
cat user.txt | grep h |sed '2c 10\twanghua\tN\t90'
字符串的替换:s
1
2
3
4
5
6
7
8
9cat user.txt | grep h
1 zhang M 19
3 cheng M 10
4 huahua M 100
cat user.txt | grep h |sed '2s/ch/wh/g'
1 zhang M 19
3 wheng M 10
4 huahua M 100
把第3行的数据里的wang 替换成heee 并写入到user.txt
1
sed -i '3s/wang/heee/g' user.txt
sed -e ‘s/zhang//g ; s/wang//g’ user.txt # -e允许多条命令顺序执行,用分号隔开,s前面不加数字表示所有行
奇数行,偶数行
1
2
3sed -n 'p;n' a.txt 输出奇数行,n表示读入下一行文本(隔行)next
sed -n 'n;p' a.txt 输出偶数行,n表示读入下一行文本(隔行)
sed -n '$=' a.txt 输出文件的行数, wc -l返回行数及文件名
awk
功能
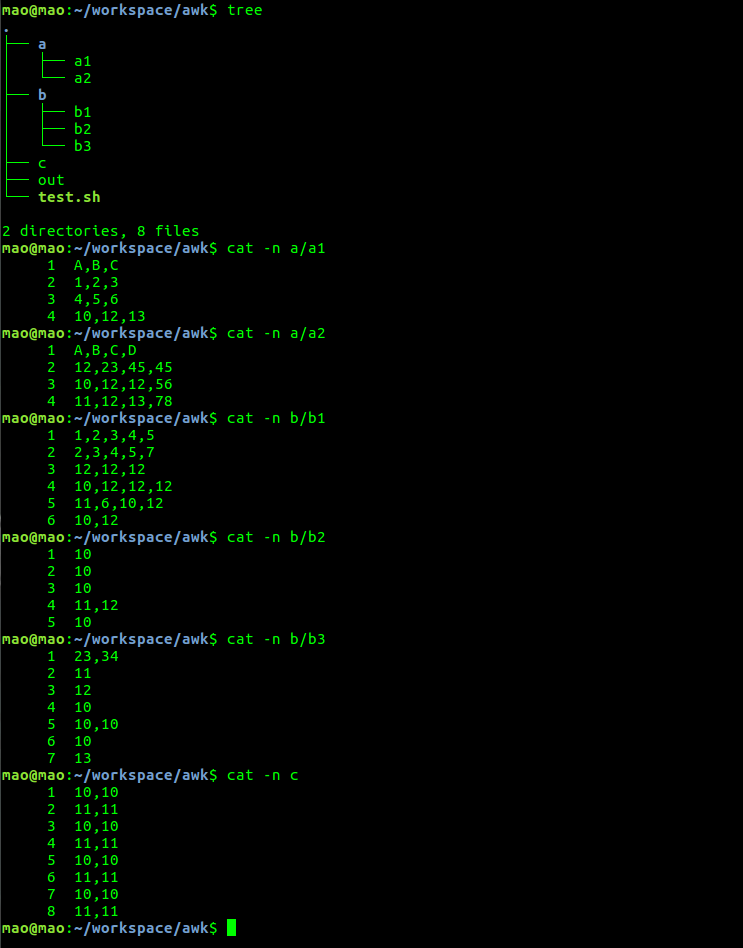
在当前路径下,递归遍历所有的文件,每个文件使用逗号分割,找出每一行第一列值为10的所有文件的记录的行号和文件名。
1
2
3
4
5
6
7
8#/usr/bin env
# 通过find递归,得到所有的文件的完整路径
files=$(find ./ -type f)
for i in $files
do
# awk的-F选项指定分割符号,-v是指定的变量,可以在print中打印,'$1=="10"是指第一列中等于10的,print NR表示的是指示的行号,uniq指的是过滤掉重复的,>>out指的是追加到out文件
awk -F "," -v mao=$PWD '$1=="10"{print NR,FILENAME}' $i | uniq >>out
done展示
文件以及文件内容(cat -n可以显示行号)
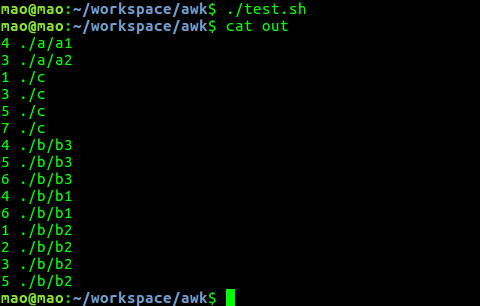
- 输出结果
- awk简单命令


