Java总结-2
五、Java
(一)基础
0. Java对象
普通对象
- markword:(1)锁信息,(2)GC信息,(3)hashcode(Identity HashCode),怎么标记这个锁是自己持有的?
- 类型指针class pointer
- 实例数据instance data
- 对齐padding
数组
- markword
- class pointer
- 数组长度length(4个字节)
- 实例数据instance data
- 对齐 padding
1.泛型?
泛型是如何实现的?
泛型是通过类型擦除实现的。
什么是泛型中的限定通配符和非限定通配符 ?
这是另一个非常流行的Java泛型面试题。限定通配符对类型进行了限制。有两种限定通配符,一种是<? extends T>它通过确保类型必须是T的子类来设定类型的上界,另一种是<? super T>它通过确保类型必须是T的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。另一方面<?>表示了非限定通配符,因为<?>可以用任意类型来替代。
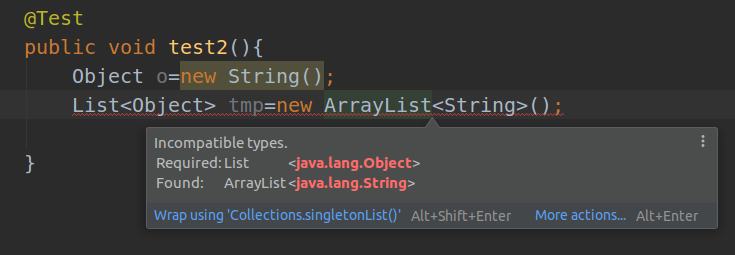
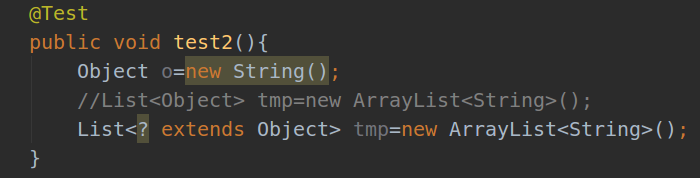
List<? extends T>和List <? super T>之间有什么区别 ?
List<? extends T>可以接受任何继承自T的类型的List,而List<? super T>可以接受任何T的父类构成的List。例如List<? extends Number>可以接受List
或List 可以把List
传递给一个接受List 编译错误。
补充(List
2.内部类?(成局静匿)
(1)成员内部类
一个类定义在一个类的内部,看起来像类的成员。
问题:
- 有隐藏的问题
- 访问:成员内部类可以无条件地访问外部类的成员,而外部类想访问成员内部类的成员却不是这么随心所欲了。在外部类中如果要访问成员内部类的成员,必须先创建一个成员内部类的对象,再通过指向这个对象的引用来访问
(2)局部内部类
定义在方法或者是一个作用域内,和成员内部类的区别在于访问权限上。
问题:
- 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
- 是不能有 public、protected、private 以及 static 修饰符的。
(3)静态内部类
静态内部类也是定义在另一个类里面的类,只不过在类的前面多了一个关键字static。静态内部类是不需要依赖于外部类的,这点和类的静态成员属性有点类似,
并且它不能使用外部类的非static成员变量或者方法
- 静态内部类是不依赖于外部类的,也就说可以在不创建外部类对象的情况下创建内部类的对象。
(4)匿名内部类
一般使用匿名内部类的方法来编写事件监听代码。同样的,匿名内部类也是不能有访问修饰符和 static 修饰符的。
3.构造器能不能override?
不可以,可以重载,不可以重写,理由:父类的私有属性以及构造器不能够被重载。
4.String,StringBulider,StringBuffer?
对方法或者被调用的方法加了同步锁。
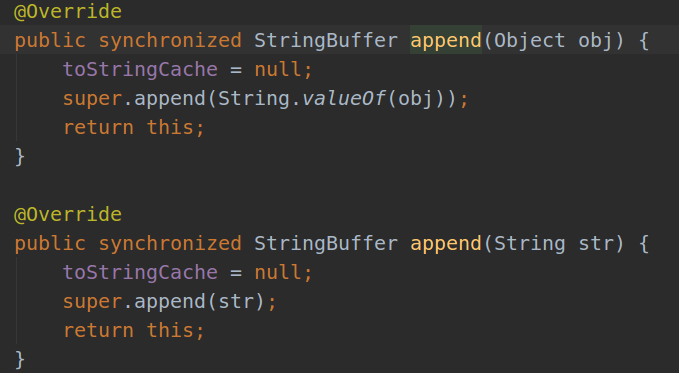
- String的基本特征,不可变类,声明为final类,当然使用类反射是可以更改的,一般用在常量申明
- StringBuffer与StringBuilder
- 内存不够,将原来的复制过来
5.static相关?(类,方法,属性,代码块)
(目的:方便在没有new的情况下使用方法和属性)
(1)修饰?
- 类
- 方法:是没有this的,因为它不依附于任何对象,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。非静态成员方法中是可以访问静态成员方法/变量的。
- 属性:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
- 代码块:用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
(2)特点
- 在static方法内部不能调用非静态方法。
- 例题:
1 | /** |
6.接口和抽象类的区别?
(1)接口?
- 一个类可以实现多个接口。
- 接口中除了static、final变量,不能有其他变量,
- 不能够有方法的实现,java 8开始支持default。
- 接口默认是:public的
- 从设计上讲:抽象是对类的抽象
(2)抽象类?
- 一个类只能继承一个抽象类。
- 抽象类中可以有属性以及方法的实现。
- 从设计上讲:是对行为的抽象。
- 抽象方法可以有public、protected和default这些修饰符(抽象方法就是为了被重写所以不能使用private关键字修饰!)
7.equals和hashcode?
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖(默认使用的地址来计算,不重写hashcode很可能不一样)
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
8.Throwable类?
(1)结构?
java.lang
Class Throwable
- java.lang.Object
- java.lang.Throwable
- All Implemented Interfaces:
Direct Known Subclasses:
常用的方法:getMessage,printStackTrace
- public string getMessage():返回异常发生时的详细信息
- public string toString():返回异常发生时的简要描述
- public string getLocalizedMessage():返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
- public void printStackTrace():在控制台上打印Throwable对象封装的异常信息
(2)常见的异常和错误?
异常(可检查的,不可检查的(运行时运行))
- ArithmeticException
- IndexOutOfBoundsException
- RuntimeException(在运行的时候抛出)
- NullPointerException
- 原则:
- 尽量捕获特定的异常
- 不要生吞异常
- 只捕获必要的代码段
- 不要使用异常处理块控制代码的流程
- throw抛出异常
- throws
- try with语法糖,自动关闭资源,(类比Python中的
| 编号 | 类型 | 代表 |
| :—- | :—————————————————————————————- | :——————————————————- |
| 1 | 检查型(在函数的声明上必须添加throws)(不是RuntimeException的派生类) | IOException,SQLException |
| 2 | 非检查型(是RuntimeException的派生类) | NullPointException,ClassCastException |
错误(Linkage Error,virtual machine Error)
- OutOfMemoryError
- StackOverflowError
(3)Throw和Throws的区别?
- Throw用于方法内部,Throws用于方法声明上
- Throw后跟异常对象,Throws后跟异常类型
- Throw后只能跟一个异常对象,Throws后可以一次声明多种异常类型
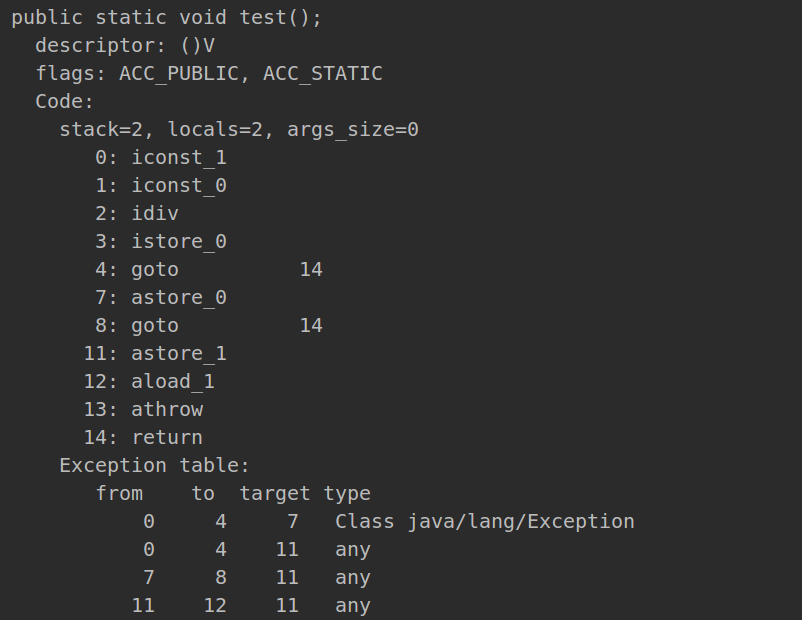
(4)异常是怎么实现的?
在编译器生成的字节码中,每一个方法都附有一个异常表(Exception Table),由四部分构成:
- from指针:指示了该异常处理器所监控的范围
- to指针:指示了该异常处理器所监控的范围
- target指针:指向异常处理器的起始位置
- 捕获的异常类型
1 | public static void test(){ |
9. OutOfMemory详解
| 名字 | 图片 | 解释 |
|---|---|---|
| Exception in thread “main” java.lang.StackOverflowError |  |
递归调用,深度太深 |
| Exception in thread “main” java.lang.OutOfMemoryError: Java heap space |  |
堆空间不够() |
| java.lang.OutOfMemoryError: GC overhead limit exceeded |  |
垃圾回收事倍功半,GC直接罢工 |
| Exception in thread “main” java.lang.OutOfMemoryError: Direct buffer memory |  |
nio分配直接内存,不够导致 |
| Exception in thread “main” java.lang.OutOfMemoryError: unable to create new native thread |  |
同一个进程创建的线程太多了,Linux默认限制为1024个。 |
方法区溢出(方法区又被称作永久代):
1 | public class RuntimeConstantPoolOOM { |
10.Collections和Arrays常见的方法?
11.反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
类名 用途 Class类 代表类的实体,在运行的Java应用程序中表示类和接口 //第1种方式获取Class对象 :通过实例对象getClass()
Person p1=new Person();
Class clazz1=p1.getClass();
//第2种方式获取Class对象:类名.class
Class clazz2=Person.class;
//第3种方式获取Class对象 Class :全类名
clazz3=Class.forName(“JavaDemo.VMTest.ReflectDemo.Person”);Field类 代表类的成员变量(成员变量也称为类的属性) Field field2=clazz.getDeclaredField(“idcard”);
field2.setAccessible(true);
field2.set(obj, “123456”);Method类 代表类的方法 Method m2=clazz.getDeclaredMethod(“show”,String.class);
m2.setAccessible(true);
m2.invoke(obj,”smt”);Constructor类 代表类的构造方法 //获取私有构造方法
Constructor cc3=clazz.getDeclaredConstructor(int.class);
//暴力访问
cc3.setAccessible(true);
Object oo3=cc3.newInstance(1);如何使用反射
(1)使用Class类,获取出被解剖的这个类的class文件对象 (2) 使用Class类方法,获取出类中的所有成员 (3) 将成员获取出来后,交给对应类,对应类中的方法,运行成员
如何获取,class文件对象
使用类的对象获取
- 每个类都使用Object作为父类,Object类方法 getClass()返回这个类的class文件对象,方法返回值Class类型对象
- 使用类的静态属性获取:类名.class 返回这个类的class文件对象.属性运行结果也是Class类型对象(并不是使用的是编译后的字节码class文件!)
- 使用Class类的静态方法获取:Class类静态方法 forName(String 类名) 传递字符串类名获取到这个类的class文件对象,方法返回值也是Class类型对象 不管用哪种方式获取的Class对象,他们都是相等的。
如何创建对象
(1)newInstance方法
(2)获取构造器
2
3
> Person p1=(Person) c.newInstance("李四","男",20);
>
12.Object方法
| 编号 | 名字 | 解释 |
|---|---|---|
| 1 | getClass | native方法,用于返回当前对象的Class对象 |
| 2 | hashCOde | native方法,用于返回对象的哈希码(将对象的内存地址转换为整数返回)哈希碰撞,hashcode降低了搜索的成本。 |
| 3 | equals | 用于比较两个对象的地址是否一样 |
| 4 | clone | 用于返回当前对象的一份拷贝 |
| 5 | toString | 返回类的名字@实例的哈希编码的十六进制字符串 |
| 6 | notify | |
| 7 | notifyAll | 唤醒监视线程 |
| 8 | wait | native方法,不可以重写,暂停线程的执行 |
| 9 | finalize | 实例被垃圾回收的时候触发的操作 |
13.POJO
POJO是Plain Ordinary Java Object的缩写,但是它通指没有使用Entity Beans的普通java对象,可以把POJO作为支持业务逻辑的协助类。
14.hashmap为什么是数组+链表,不是数组+数组?
15.数组为什么要连续存放?
16.包装类和基础类的区别?
拆箱装箱
17.Java中 try..catch关闭流的语法糖?
18.final,finally,finalize?
- final修饰类,方法,变量,为什么要final?不想被修改。
- finally:出现异常的时候,重要的代码会被执行(比如关闭数据库连接池)
- finalize:定义在Object类中,垃圾回收之前调用,在对象回收以前释放资源,没一个对象的finalize方法只会被执行一次,在Java9中已经抛弃了,缺陷:不能保证GC马上执行。finalize执行的流程:在GC的时候判断有没有覆盖finalize,实现了的话就会加入F-QUEUE队列,再次判断reachable是否复活还是回收。进入队列等待低优先级的线程来处理,所以并不一定会被回收。
19.面向对象的原则
- 单一职责原则(Single Responsibility Principle)每一个类应该专注于做一件事情。
- 里氏替换原则(Liskov Substitution Principle)超类存在的地方,子类是可以替换的。
- 依赖倒置原则(Dependence Inversion Principle)实现尽量依赖抽象,不依赖具体实现。
- 接口隔离原则(Interface Segregation Principle)应当为客户端提供尽可能小的单独的接口,而不是提供大的总的接口。
- 迪米特法则(Law Of Demeter)又叫最少知识原则,一个软件实体应当尽可能少的与其他实体发生相互作用。
- 开闭原则(Open Close Principle)面向扩展开放,面向修改关闭。
- 组合/聚合复用原则(Composite/Aggregate Reuse Principle CARP)尽量使用合成/聚合达到复用,尽量少用继承。原则: 一个类中有另一个类的对象。
20.多态相关
1 | 下列代码的输出结果是: |
a - function in B
1、属性不存在重写,只有方法(非私有方法、非静态方法、非final方法) 才存在重写,才能发生多态;
2、向上转型
21.字符串编码的区别?
22.Math.floor, Math.ceil,Math.round?
| 编号 | 名称 | 含义 | 例子 |
|---|---|---|---|
| 1 | Math.floor | 小于等于自身(向下取整) | Math.floor(-11.5)=-12.0 Math.floor(11.5)=11.0 |
| 2 | Math.ceil | 大于等于自身(向上取整) | Math.ceil(-11.5)=-11.0 Math.ceil(11.5)=12.0 |
| 3 | Math.round | 加0.5向下取整 | Math.round(-11.4)=-11 Math.round(-11.6)=-12 |
- ceil 英语含义是天花板
- floor英语含义是地板
1 | ---------ceil------------ |
23.修饰范围
| 编号 | 关键字 | 修饰位置 |
|---|---|---|
| 1 | static(不想新建对象使用) | 类,方法,属性,代码块(执行一次) |
| 2 | final(不想被修改) | 类,方法,变量 |
| 3 | synchronized | 方法,代码块(锁定一个对象) |
24. equals和hashcode
- 如果两个对象相等,那么它们的hashCode()值一定相同。这里的相等是指,通过equals()比较两个对象时返回true。
- 如果两个对象hashCode()相等,它们并不一定相等
(二)容器
0.整体架构
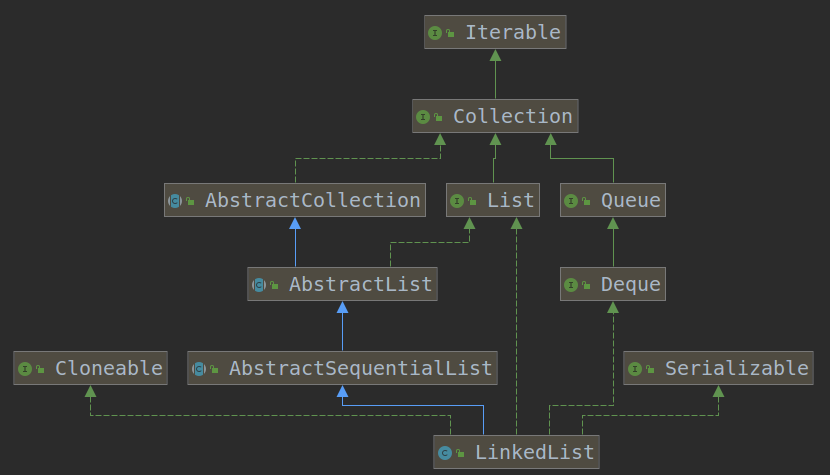
图中的绿色的虚线代表实现,绿色实线代表接口之间的继承,蓝色实线代表类之间的继承。
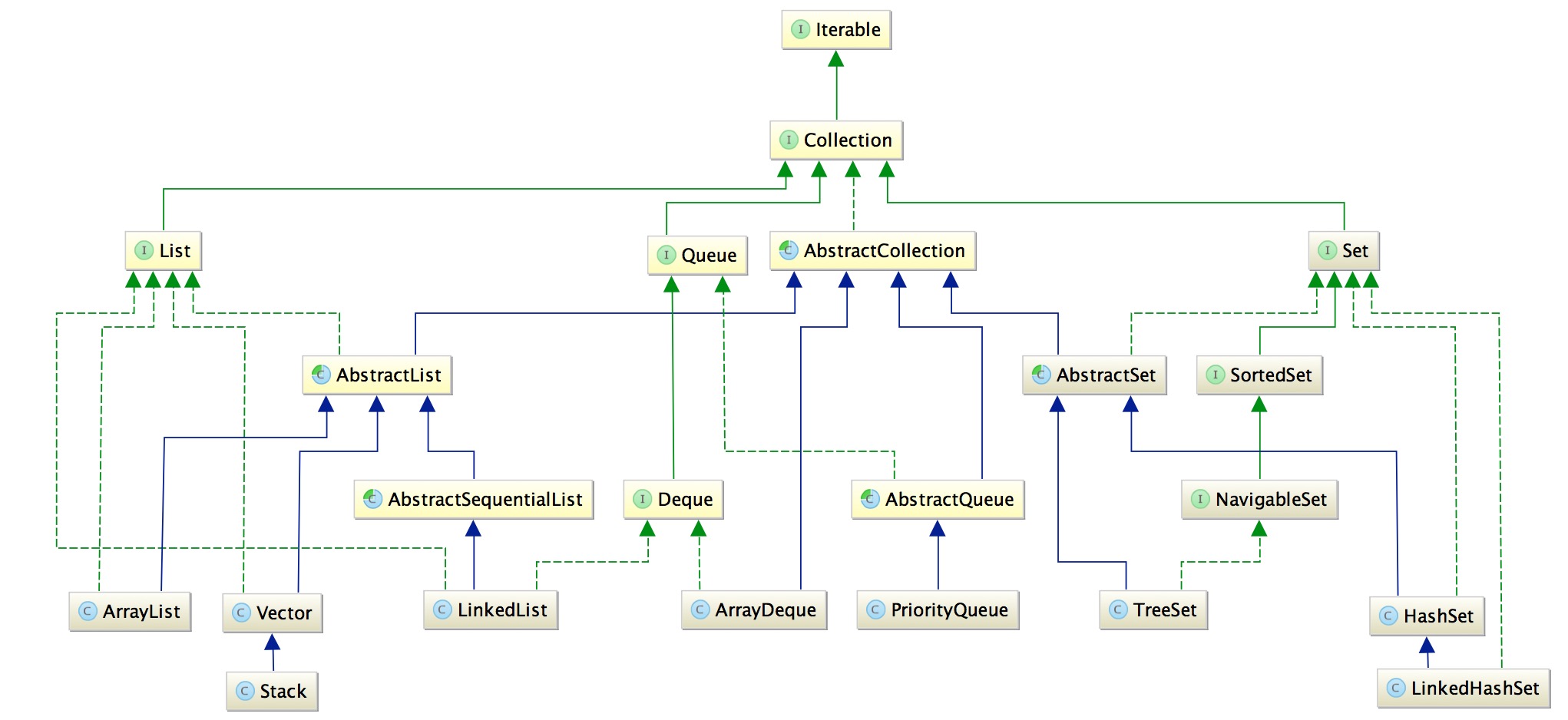
1.HashMap?
并发场景下如果要保证一种可行的方式是使用 Collections.synchronizedMap()方法来包装我们的 HashMap。但这是通过使用一个全局的锁来同步不同线程间的并发访问,因此会带来不可忽视的性能问题。
遍历(四种方式)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
> > public static void main(String[] args) {
> > Map<String,Integer> map=new HashMap<>();
> > for(int i=0;i<5;i++){
> > map.put("key_"+String.valueOf(i),i);
> > }
> > //(1)使用keySet
> > for (String key:map.keySet()){
> > System.out.println(key+":"+map.get(key));
> > }
> >
> > System.out.println("-----------------------------------");
> >
> > //(2)entrySet
> > for (Map.Entry<String,Integer> entry:map.entrySet()){
> > System.out.println(entry.getKey()+":"+entry.getValue());
> > }
> >
> > System.out.println("-----------------------------------");
> >
> > //(3)和(2)是一致的
> > Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
> > for(Map.Entry<String,Integer> entry:entrySet){
> > System.out.println(entry.getKey()+":"+entry.getValue());
> > }
> >
> > System.out.println("-----------------------------------");
> >
> > //(4)使用Iterator
> > Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();//上下相同, 这个清晰一些
> > while (it.hasNext()) {
> > Map.Entry<String, Integer> tmp=it.next();
> > System.out.println(tmp.getKey()+":"+tmp.getValue());
> > }
> >
> > }
> > }
> >
> >
2.ArrayList的扩容?(扩容为原来的1.5倍)
(1)先从 ArrayList 的构造函数
| 编号 | 构造函数 | 意义 |
|---|---|---|
| 1 | 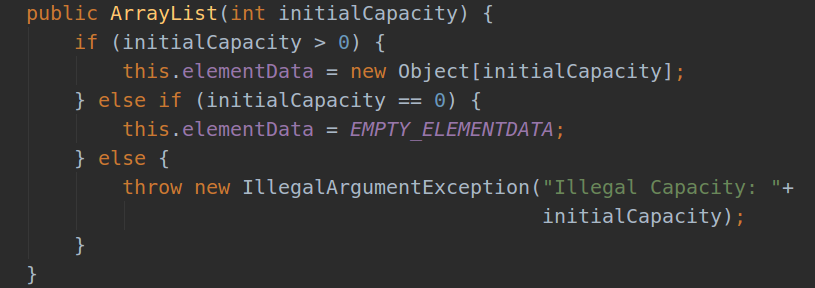 |
指定了初始化的容量大小 |
| 2 | 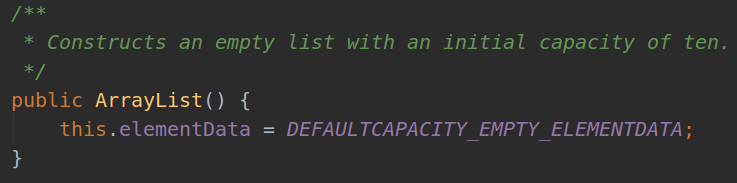 |
默认为空,在add的时候会生成一个大小为10的ArrayList |
| 3 | 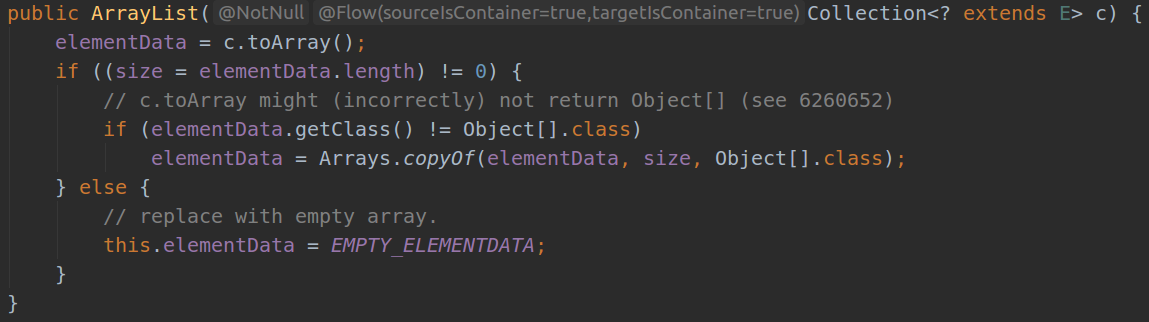 |
使用集合来构造,会拷贝集合中的值,使用集合大小进行初始化 |
(2)扩容(通常大小会变为原来大小的1.5倍,注意和HashMap的扩容机制进行比较)
| 编号 | 方法 | 解释 |
|---|---|---|
| 1 | add | 确保判断当前要加入的有空间 |
| 2 | ensureCapacityInternal | 和默认的大小10进行比较 |
| 3 | ensureExplicitCapacity | 判读是不是需要扩容,需要扩容就进行扩容 |
| 4 | grow | 将原来的大小变为1.5倍,看看符合要求不,不符合,就是用需求的大小,如果计算出的新的大小必最大值还大,就是用hugeCapacity |
| 5 | hugeCapacity | 就是使用最大的整数进行初始化 |
| 6 | ensureCapacity | 这个函数是提供给用户使用的,可以节约时间 |
(3)补充
System.arraycopy()
和Arrays.copyOf()方法//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
System.arraycopy(elementData, index, elementData, index + 1, size - index);
使用
Arrays.copyOf()方法主要是为了给原有数组扩容
3.HashMap的扩容?(扩容为原来的两倍)
HashMap的扩容要和ArrayList的扩容进行区分,HashMap的扩容的真正原因是为了回避Hash冲突,当table中已经倍占用了75%(默认负载因子)就需要进行扩容,扩容的大小为原来的两倍。
- 时机:阈值=负载因子×table大小
- 扩容table
- rehash
4.HashMap和HashTable的区别?
| 区别 | HashMap | HashTable |
|---|---|---|
| 底层实现 | 1.8:Node数组+红黑树,1.8之前(链表散列) | 数组+链表(链表散列) |
| 扩容机制 | 默认是16,扩容翻倍;HashMap 会将其扩充为2的幂次方大小(HashMap 中的tableSizeFor()方法保证)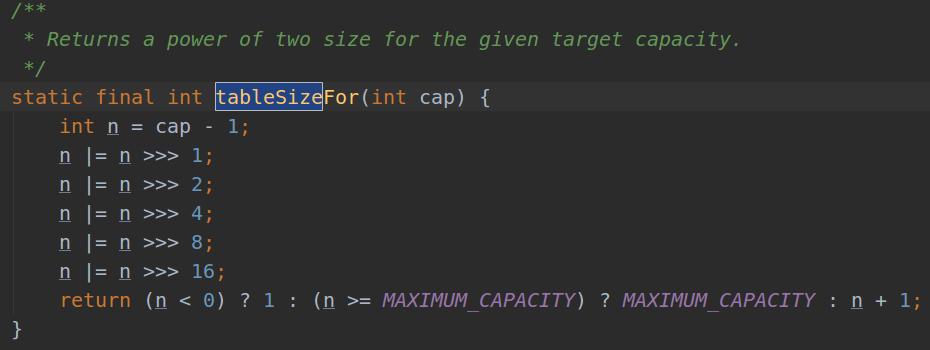 |
默认是11,扩容2n+1;指定的话,将会按照指定大小。 |
| 效率 | 相对高 | 相对低一些 |
| 对Null key 和Null value的支持 | null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null | 但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException |
| 线程是否安全 | HashMap 是非线程安全的 | HashTable 内部的方法基本都经过synchronized 修饰 |
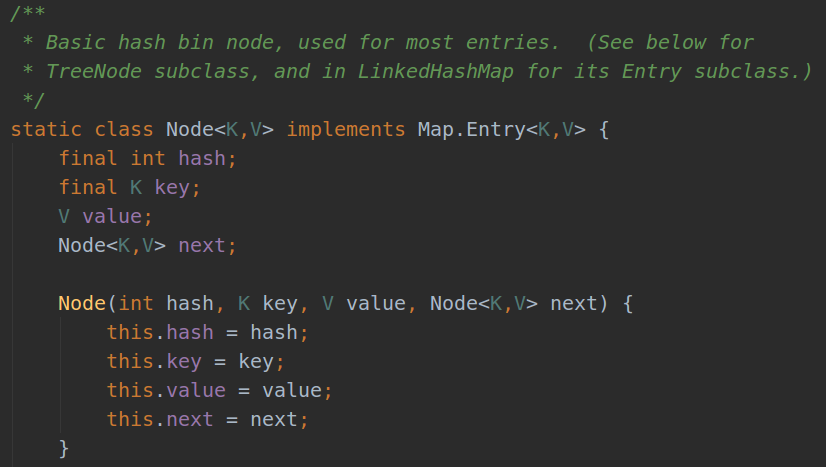
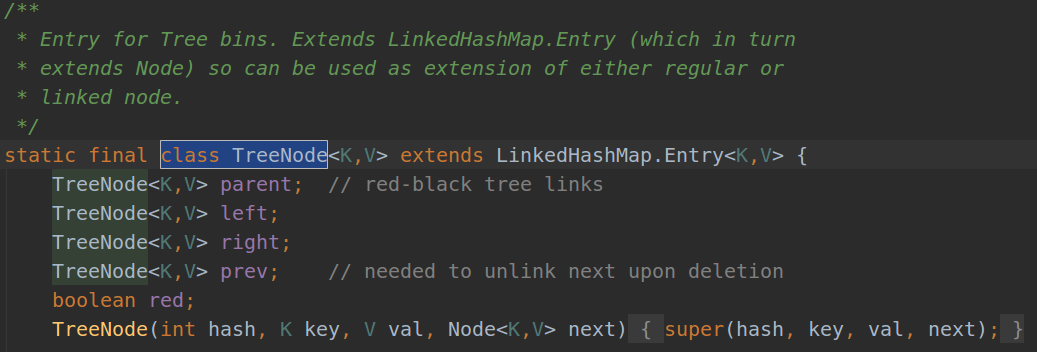
5.HashMap中的Node,及其类型?
(1)Node(实现接口Map.Entry)
(2)TreeNode(继承自LinkedHashMap.Entry)
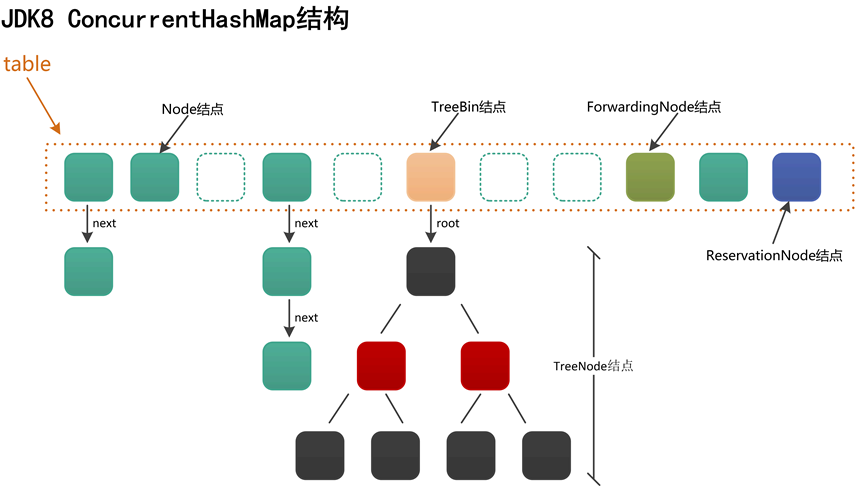
(3)ConcurrentHash的节点?
| 编号 | 名字 | 解释 |
|---|---|---|
| 1 | Node结点 | 默认链接到table[i]——桶上的结点就是Node结点。 |
| 2 | TreeNode结点 | TreeNode就是红黑树的结点,TreeNode不会直接链接到table[i]——桶上面,而是由TreeBin链接,TreeBin会指向红黑树的根结点。 |
| 3 | TreeBin节点 | TreeBin相当于TreeNode的代理结点。TreeBin会直接链接到table[i]——桶上面,该结点提供了一系列红黑树相关的操作,以及加锁、解锁操作。 |
| 4 | ForwardingNode节点 | ForwardingNode结点仅仅在扩容时才会使用。 |
| 5 | ReservationNode节点 | 保留结点,ConcurrentHashMap中的一些特殊方法会专门用到该类结点。 |
6.ArrayLis实现
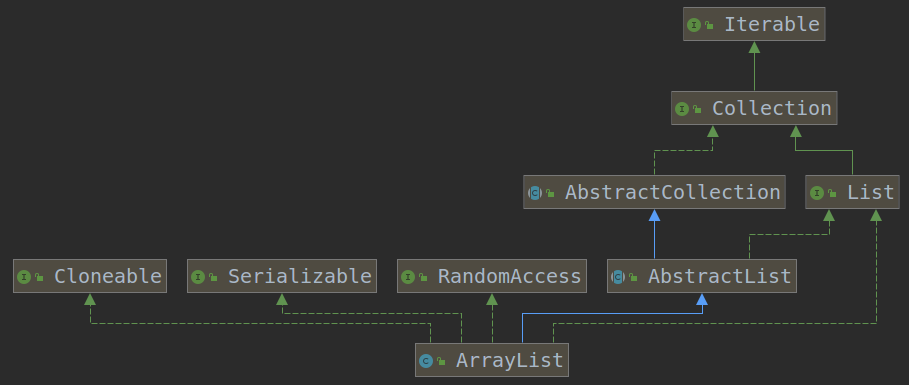
实现接口
- List
- RandomAccess
- Cloneable
- java.io.Serializable
继承的类
- AbstractList
内部类
- private class Itr implements Iterator
- private class ListItr extends Itr implements ListIterator
- private class SubList extends AbstractList
implements RandomAccess - static final class ArrayListSpliterator
implements Spliterator
ArrayList有四个内部类,其中的Itr是实现了Iterator接口,同时重写了里面的hasNext(),next(),remove()等方法;其中的ListItr继承Itr,实现了ListIterator接口,同时重写了hasPrevious(),nextIndex(),previousIndex(),previous(),set(E e),add(E e)等方法,所以这也可以看出了 Iterator和ListIterator的区别:ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
- private class Itr implements Iterator
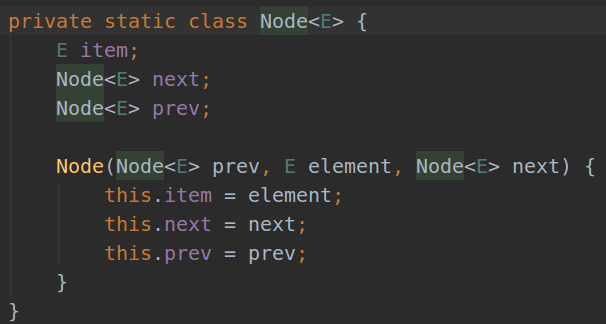
7.LinkedList实现
- LinkedList是通过双向链表实现的!
8.TreeSet,TreeMap
- TreeMap底层是一棵红黑树,TreeMap实现的是NavigableMap
- 个人认为TreeSet之于TreeMap和HashSet之于HashMap是一样的。
(三)并发
1.Java内存模型?《深入理解Java虚拟机》
深入理解Java虚拟机中说:Java虚拟机视图定义一种Java内存模型(Java memory model)来屏蔽各种硬件和操作系统之间的内存访问差异,实现Java程序在各种平台下都能够达到一致性访问的效果。定义了程序中各个变量的访问规则,特别注意的是,这些变量不包括局部变量和方法参数!,因为这些是方法私有的!
2.单例模式的实现?
- 双重检查加锁(恶汉模式)
1 | public class Singleton { |
- 静态内部类模式(恶汉模式)
1 | public class Singleton2 { |
3.线程的实现方式?怎么使用lambda的形式?
ps:Python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的、原始的线程以及一个简单的锁。
(1)Thread——————run()方法
(2)Runnable——————run()方法
(3)Callable—————call()—————FutureTask
1 | package JavaBasic; |
(4)使用匿名内部类
1 | new Thread(()->{ |
补充:
对于同一个Thread使用两次start将会有什么结果?

4.线程池
(1) 为什么要使用线程池?
- 在执行大量异步任务的时候能够提供良好的性能。(线程的创建和销毁是有时间开销的)
- 提供了一种良好的资源限制和管理的方式。
(2) 线程池的架构图

| 编号 | 名称 | 说明 |
|---|---|---|
| 1 | Executor | 只有execute方法 |
| 2 | ExecutorService(继承) | |
| 3 | AbstractExecutorService(实现) | |
| 4 | ThreadPoolExecutor(继承) | 构造器有七个参数 |
| 5 | Executors(只是一个工具类) |
注意:接口和接口之间不可以使用implements,但是是可以使用继承的!,其实很好理解:implements是需要将所有的方法都实现的,但是interface是不能够包含具体的实现的!切记!
ThreadPoolExecutor继承了AbstractExecutorService,AbstractExecutorService实现了ExecutorService接口,ExecutorService继承了Executor接口。
- Executors是一个工具类,主要的方法有:
- Executors.newFixedThreadPool
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
- Executors.newCachedThreadPool
1 | public static ExecutorService newCachedThreadPool() { |
- Executors.newSingleThreadExecutor(一个看来称不上是pool)
1 | public static ExecutorService newSingleThreadExecutor() { |
ThreadPoolExecutor参数(7个参数)
- @param corePoolSize 核心线程池中的最大线程数
- @param maximumPoolSize 总线程池中的最大线程数
- @param keepAliveTime 空闲线程的存活时间
- @param unit keepAliveTime的单位
- @param workQueue 任务队列, 保存已经提交但尚未被执行的线程
- @param threadFactory 线程工厂(用于指定如果创建一个线程)
- @param handler 拒绝策略 (当任务太多导致工作队列满时的处理策略)
线程池的状态(高三位表示状态,第29位表示线程的数量),ThreadPoolExecutor的ctl属性,三位,取值范围共计5个,特别注意,这一个变量是原子类型的,在谈论原子类型的使用的时候,可以拿来举例!,还要注意的是,只有在线程池的状态等于-1的时候不会产生中断,当状态大于等于0的时候将会产生中断。
RUNNING -1 接受新任务, 且处理已经进入阻塞队列的任务
SHUTDOWN 0 不接受新任务, 但处理已经进入阻塞队列的任务
STOP 1 接受新任务, 且不处理已经进入阻塞队列的任务, 同时中断正在运行的任务
TIDYING 2 所有任务都已终止, 工作线程数为0, 线程转化为TIDYING状态并准备调用terminated方法
TERMINATED 3 terminated方法已经执行完成
execute执行流程图
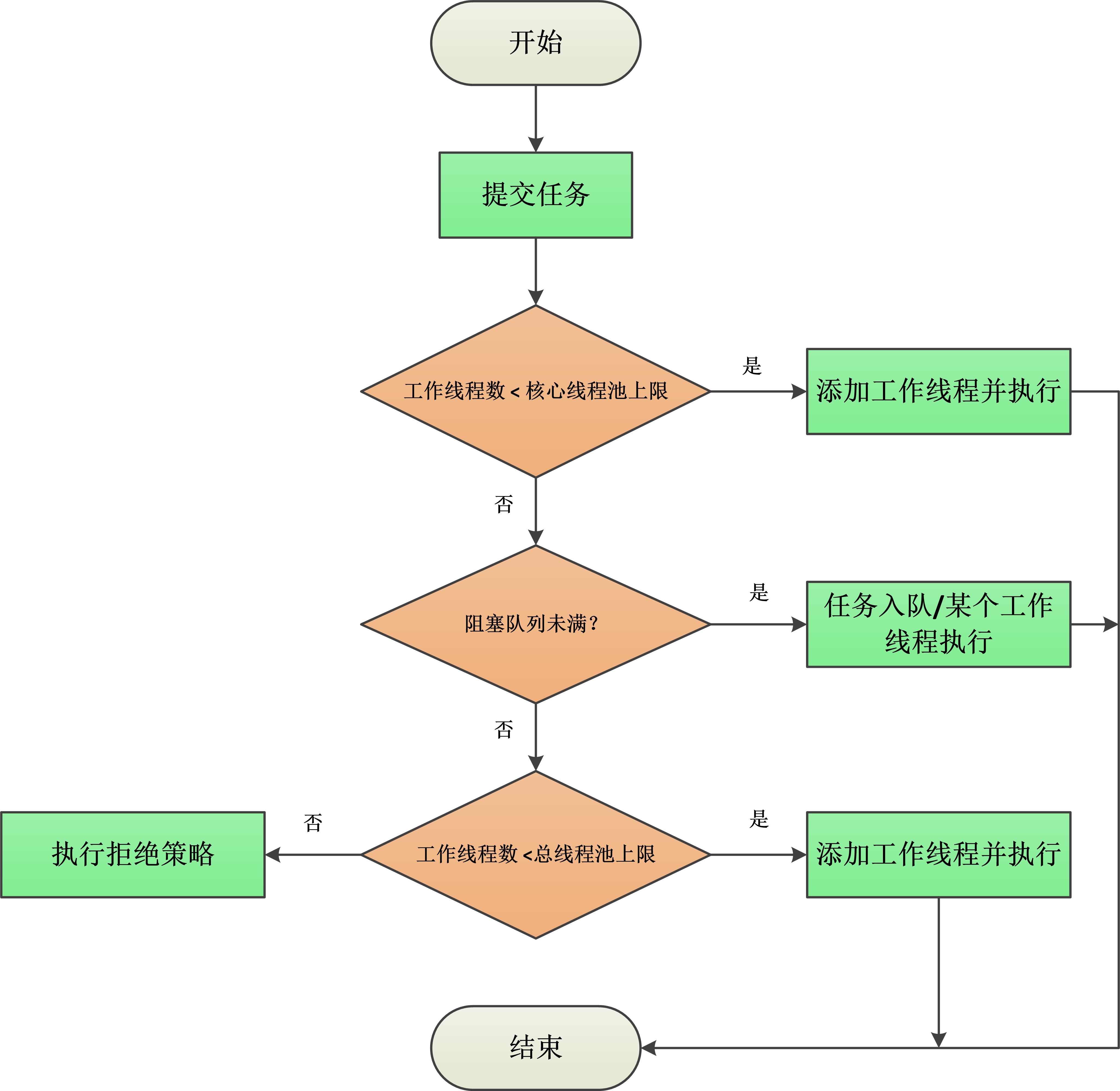
场景:今天是周末,一银行网点只开放了几个窗口,当前值班窗口的数量就是核心线程池的上限。一开始,顾客陆续进来,值班的窗口还有空闲的,则进来一个人就可以直接去柜台办理。随着人数的增加,当天值班窗口全部有人在办理业务,这个时候有人进来,就要在大厅里找个座位坐下来等待,大厅的座位就是阻塞队列。但是,当天人数越来越多,连大厅的座位都坐满了人,这个时候这个网点领导将会通知将当天休息的窗口也打开(所有的窗口数目就是总的线程池上限),当人数还继续增加的话,处于安全考虑,银行就会拒绝继续进入,这就是执行了拒绝策略。
- ThreadPoolExecutor:
1
2> >private static ExecutorService executor = new ThreadPoolExecutor(13, 13,60L, TimeUnit.SECONDS,new ArrayBlockingQueue(13));
> >- 使⽤ Executors 创建:
FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列⻓度为 Integer.MAX_VALUE,可能堆积⼤量的请求,从⽽导致OOM。 CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ==,可能会创建⼤量线程,从⽽导致OOM。
- guava提供的ThreadFactoryBuilder来创建线程池:
通过上述⽅式创建线程时,不仅可以避免OOM的问题,还可以⾃定义线程名称,更加⽅便的出错的时候溯源。
- 拒绝策略
| 编号 | 拒绝策略 | 解释 |
| :—- | :————————— | :—————————————————- |
| 1 | CallerRunsPolicy | 使用调用者所在的线程来执行任务 |
| 2 | AbortPolicy | 抛出异常 |
| 3 | DiscardPolicy | 默认丢弃,不抛出异常 |
| 4 | DiscardOldestPolicy | 调用poll抛弃一个任务,执行当前的任务 |
5.Java 并发包提供了哪些并发工具类?
juc-locks 锁框架
juc-locks锁框架中一共就三个接口:Lock、Condition、ReadWriteLock
ReadWriteLock: 一个单独的接口(未继承Lock接口),该接口提供了获取读锁和写锁的方法。
ReentrantLock:ReentrantLock内部通过内部类实现了AQS框架(AbstractQueuedSynchronizer)的API来实现独占锁的功能。
ReentrantReadWriteLock:ReentrantReadWriteLock使得多个读线程同时持有读锁(只要写锁未被占用),而写锁是独占的。写锁可以降级成读锁,读锁不能升级成写锁。
juc-atomic 原子类框架( J.U.C之atomic框架:Unsafe类)
其实底层就是通过Unsafe类实现的一种比较并交换的算法,大致的结构如下(具体入参,根据上下文有所不同):
boolean compareAndSet(expectedValue, updateValue);当希望修改的值与expectedValue相同时,则尝试将值更新为updateValue,更新成功返回true,否则返回false。Unsafe类,来源于
sun.misc包。该类封装了许多类似指针操作,可以直接进行内存管理、操纵对象、阻塞/唤醒线程等操作。Java本身不直接支持指针的操作,所以这也是该类命名为Unsafe的原因之一。juc-sync 同步器框架
juc-collections 集合框架
juc-executors 执行器框架
- 线程池
- Future模式,Future接口仅仅定义了5个方法。
- Fork/Join框架
(1)提供了比 synchronized 更加高级的各种同步结构
包括 CountDownLatch、CyclicBarrier、Sempahore 等,可以实现更加丰富的多线程操作,比如利用 Semaphore 作为资源控制器,限制同时进行工作的线程数量。
- CountDownLatch,允许一个或多个线程等待某些操作完成
- CyclicBarrier,一种辅助性的同步结构,允许多个线程等待到达某个屏障
- CountDownLatch 是不可以重置的,所以无法重用;而 CyclicBarrier 则没有这种限制,可以重用。
- CountDownLatch 的基本操作组合是 countDown/await。调用 await 的线程阻塞等待countDown 足够的次数,不管你是在一个线程还是多个线程里 countDown,只要次数足够即可。所以就像 Brain Goetz 说过的,CountDownLatch 操作的是事件。
- CyclicBarrier 的基本操作组合,则就是 await,当所有的伙伴(parties)都调用了 await,才会继续进行任务,并自动进行重置。
- Semaphore,Java 版本的信号量实现,总的来说,Semaphore 就是个计数器,其基本逻辑基于 acquire/release.
(2)各种线程安全的容器
比如最常见的 ConcurrentHashMap、有序的ConcunrrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList 等。
Concurrent
CopyOnWrite
Blocking
(3)并发队列实现
如各种 BlockedQueue 实现,比较典型的 ArrayBlockingQueue、SynchorousQueue 或针对特定场景的 PriorityBlockingQueue 等。
(4)强大的 Executor 框架
可以创建各种不同类型的线程池,调度任务运行等,绝大部分情况下,不再需要自己从头实现线程池和任务调度器
(5)AQS框架(AbstractQueuedSynchronizer抽象类)
- AQS利用了模板方法模式,其中大多数方法都是final或是private的,我们把这类方法称为Skeleton Method,也就是说这些方法是AQS框架自身定义好的骨架,子类是不能覆写的。
- 支持中断、超时
- 支持独占模式和共享模式
- 支持Condition条件等待
AQS方法说明:
- CAS操作
- 等待队列的核心操作
- 资源的获取操作
- 资源的释放操作
三个基本问题:
- 同步状态(synchronization state)的管理
- 阻塞/唤醒线程的操作
- 线程等待队列的管理
CLH队列
CLH队列中的结点是对线程的包装,结点一共有两种类型:独占(EXCLUSIVE)和共享(SHARED)。 每种类型的结点都有一些状态,其中独占结点使用其中的CANCELLED(1)、SIGNAL(-1)、CONDITION(-2),共享结点使用其中的CANCELLED(1)、SIGNAL(-1)、PROPAGATE(-3)。
Node节点
6.哪些队列是有界的,哪些是无界的?
从源码的角度,常见的线程安全队列是如何实现的,并进行了哪些改进以提高性能表现?
(1)有界or无界
- ArrayBlockingQueue 是最典型的的有界队列,其内部以 final 的数组保存数据,数组的大小就决定了队列的边界,所以我们在创建 ArrayBlockingQueue 时,都要指定容量
- LinkedBlockingQueue,容易被误解为无边界,但其实其行为和内部代码都是基于有界的逻辑实现的,只不过如果我们没有在创建队列时就指定容量,那么其容量限制就自动被设置为 Integer.MAX_VALUE,成为了无界队列。
- SynchronousQueue,每个删除操作都要等待插入操作,反之每个插入操作也都要等待删除动作。那么这个队列的容量是多少呢?是 1 吗?其实不是的,其内部容量是 0。
- PriorityBlockingQueue 是无边界的优先队列,虽然严格意义上来讲,其大小总归是要受系统资源影响
- DelayedQueue 和 LinkedTransferQueue 同样是无边界的队列。
(2)安全?
- BlockingQueue 基本都是基于锁实现
- 类似 ConcurrentLinkedQueue 等,则是基于 CAS 的无锁技术,不需要在每个操作时使用锁,所以扩展性表现要更加优异
7.生产者 - 消费者?
- (1)传统版synchronized: sync———————->wait——————->notify
- (2)传统版lock: lock—————>await—————>Signal
- (3)阻塞队列+原子类
2
3
4
> * 2 判断 干活 通知
>* 3 虚假唤醒
>
1 | package JavaDemo.MultiThreadTest; |
1 | class ShareData{ |
1 | package JavaDemo.MultiThreadTest; |
8.synchronized和lock的区别?用lock的好处?
| 区别 | synchronized | lock |
|---|---|---|
| 原始构成 | (关键字)jvm层面,底层通过monitor对象来完成,monitorenter和monitorexit(两个monitorexit) | (具体类)Lock是具体的类(java.concurrent.locks.Lock),是api层面的锁(使用java p) |
| 使用方法 | 自动释放 | 需要使用try、finally释放 |
| 等待是否可中断 | 不可以被中断 | 可以被中断,lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。 |
| 加锁是否公平 | 非公平锁 | 默认是非公平锁,构造函数传参,true公平,false非公平 |
| 锁绑定多个条件 | 没有 | 可以用来实现分组唤醒需要唤醒的线程,可以精确唤醒,synchronized随机唤醒一个或者多个 |
1 | import java.util.concurrent.locks.Condition; |
9.JUC主要包含的内容?透彻理解Java并发编程
(1)概览
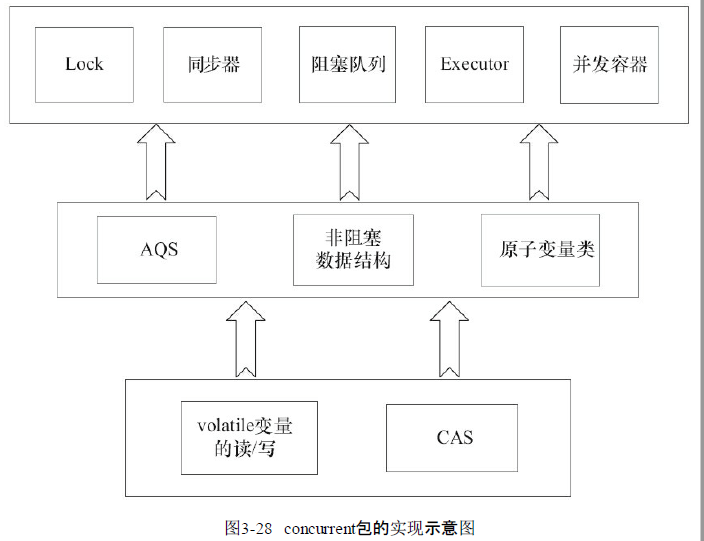
(2) 并发容器
- CopyOnWrite*(List,Set)

Concurrent*(SkipListSet,SkipListMap,Map,LinkedQueue)

Blocking*(Queue, Deque)(Array,Linked,Priority)
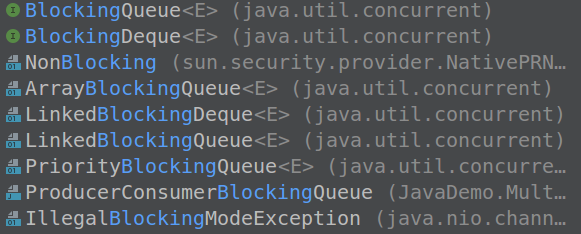
| List,Set | Map | Queue |
|---|---|---|
| CopyOnWriteArrayList CopyOnWriteArraySet ConcurrentSkipListSet |
ConcurrentHashMap ConcurrentSkipListMap |
ArrayBlockingQueue LinkedBlockingQueue ConcurrentLinkedQueue ConcurrentLinkedDeque |
| 类 | ji(Ctrl+H,Alt+7) | 并发 | |
|---|---|---|---|
| CopyOnWriteArrayList | Cloneable (java.lang) List (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) RandomAccess (java.util) Serializable (java.io) |
 |
ReentrantLock,读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。CopyOnWriteArrayList 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。 |
| CopyOnWriteArraySet | AbstractSet (java.util) AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Set (java.util) Collection (java.util) Serializable (java.io) |
A {@link java.util.Set} that uses an internal {@link CopyOnWriteArrayList} for all of its operations. Thus, it shares the same basic properties*  |
ReentrantLock |
| ConcurrentSkipListSet | AbstractSet (java.util) AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Set (java.util) Collection (java.util) Iterable (java.lang) Cloneable (java.lang) NavigableSet (java.util) SortedSet (java.util) Set (java.util) Collection (java.util) Iterable (java.lang) Serializable (java.io) |
||
| ConcurrentHashMap | AbstractMap (java.util) Map (java.util) Object (java.lang) ConcurrentMap (java.util.concurrent)Map (java.util) Serializable (java.io) |
 |
JDK1.8: Node + CAS + Synchronized |
| ConcurrentSkipListMap | AbstractMap (java.util) Map (java.util) Object (java.lang) Cloneable (java.lang) ConcurrentNavigableMap (java.util.concurrent) ConcurrentMap (java.util.concurrent) Map (java.util) NavigableMap (java.util)SortedMap (java.util) Map (java.util) Serializable (java.io) |
使用跳表实现Map 和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。JDK 中实现这一数据结构的类是ConcurrentSkipListMap。 | |
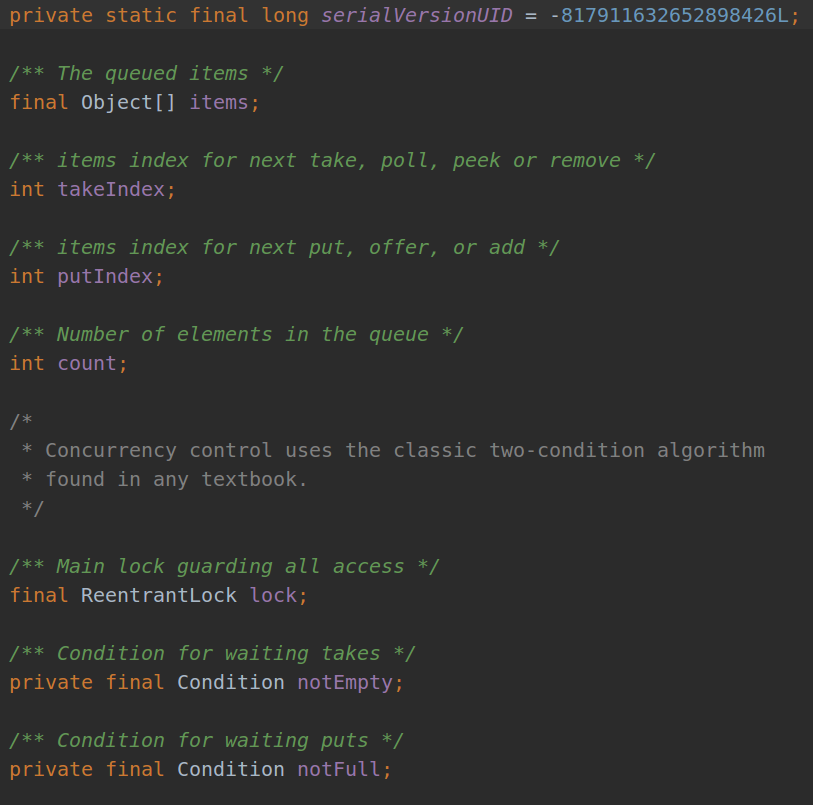
| ArrayBlockingQueue | AbstractQueue (java.util) AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Queue (java.util) Collection (java.util) Iterable (java.lang) BlockingQueue (java.util.concurrent) Queue (java.util) Collection (java.util) Iterable (java.lang) Serializable (java.io) |
 |
Lock+Condition |
| LinkedBlockingQueue | AbstractQueue (java.util) AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Queue (java.util) Collection (java.util) Iterable (java.lang) BlockingQueue (java.util.concurrent) Queue (java.util) Collection (java.util) Iterable (java.lang) Serializable (java.io) |
ArrayBlockingQueue与LinkedBlockingQueue的比较? 相同点: ArrayBlockingQueue和LinkedBlockingQueue都是通过condition通知机制来实现可阻塞式插入和删除元素,并满足线程安全的特性; ArrayBlockingQueue底层是采用的数组进行实现,而LinkedBlockingQueue则是采用链表数据结构; 不同点: ArrayBlockingQueue插入和删除数据,只采用了一个lock,而LinkedBlockingQueue则是在插入和删除分别采用了 putLock和takeLock,这样可以降低线程由于线程无法获取到lock而进入WAITING状态的可能性,从而提高了线程并发执行的效率。 |
|
| ConcurrentLinkedQueue | AbstractQueue (java.util) AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Queue (java.util) Collection (java.util) Iterable (java.lang) Queue (java.util) Collection (java.util) Iterable (java.lang) Serializable (java.io) |
阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。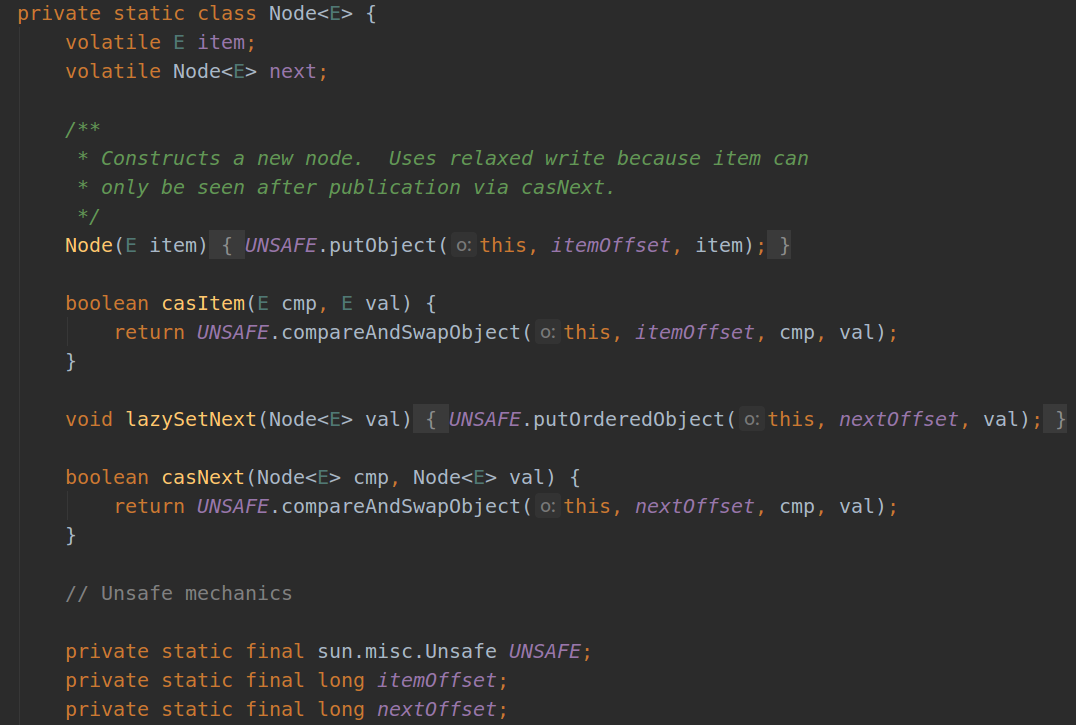 |
无锁算法,底层基于自旋+CAS的方式实现。 |
| ConcurrentLinkedDeque | AbstractCollection (java.util) Collection (java.util) Iterable (java.lang) Object (java.lang) Deque (java.util) Queue (java.util) Collection (java.util) Iterable (java.lang) Serializable (java.io) |
- CopyOnWrite*:只有两个
- Concurrent*
- Blocking*
(3)ConcurrentHashMap
(注意,和HashMap相比较,实现上,ConcurrentHashMap节点种类是5种)
针对ConcurrentHashMap的讲解要分析以下的几个点(注意条理!)
- 构成上,分析五个Node
- Node
- TreeBin
- TreeNode
- ForwardingNode
- ReservationNode
- 操作上,分析:
- get方法采用了unsafe方法,来保证线程安全。
- 如果table[i]的key和待查找key相同,那直接返回;
- 如果table[i]对应的结点是特殊结点(hash值小于0),则通过find方法查找;
- 如果table[i]对应的结点是普通链表结点,则按链表方式查找。
- put
- 首次初始化table —— 懒加载
- table[i]对应的桶为空,最简单的情况,直接CAS操作占用桶
table[i]即可。- 发现ForwardingNode结点,说明此时table正在扩容,则尝试协助进行数据迁移
- 出现hash冲突,也就是table[i]桶中已经有了结点
- table[i]的结点类型为Node——链表结点时,就会将新结点以“尾插法”的形式插入链表的尾部。
- 当table[i]的结点类型为TreeBin——红黑树代理结点时,就会将新结点通过红黑树的插入方式插入。
- putVal方法的最后,涉及将链表转换为红黑树 —— treeifyBin ,但实际情况并非立即就会转换,当table的容量小于64时,static final int MIN_TREEIFY_CAPACITY = 64;出于性能考虑,只是对table数组扩容1倍——tryPresize
- 计数(分段计数)
- 扩容问题
- table数组的扩容,一般就是新建一个2倍大小的槽数组,这个过程通过由一个单线程完成,且不允许出现并发。(时机:和负载因子有关系)
- 数据迁移
- 链表
- 红黑树


1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
(4)原子类
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
| 编号 | 名字 | 解释 |
|---|---|---|
| 1 | 基本类型 | AtomicInteger:整型原子类 ,AtomicLong:长整型原子类 ,AtomicBoolean :布尔型原子类 |
| 2 | 数组类型 | AtomicIntegerArray:整型数组原子类, AtomicLongArray:长整型数组原子类, AtomicReferenceArray:引用类型数组原子类 |
| 3 | 引用类型 | CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始, 提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象 里来进行 CAS 操作.所以我们可以使用锁或者利用 AtomicReference类把多个共享变量合并成一个共享变量来操作。 AtomicReference:引用类型原子类,AtomicStampedReference:原子更新引用类型里的字段原子类AtomicMarkableReference:原子更新带有标记位的引用类型 |
| 4 | 对象的属性修改类型 | AtomicIntegerFieldUpdater:原子更新整型字段的更新器,AtomicLongFieldUpdater:原子更新长整型字段的更新器 |
引用类型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
> public class AtomicReferenceTest {
> public static void main(String[] args) {
> AtomicReference<Person> ar = new AtomicReference<Person>();
> Person person = new Person("SnailClimb", 22);
> ar.set(person);
> Person updatePerson = new Person("Daisy", 20);
> ar.compareAndSet(person, updatePerson);
> System.out.println(ar.get().getName());
> System.out.println(ar.get().getAge());
> }
> }
>class Person {
> private String name;
> private int age;
> public Person(String name, int age) {
> super();
> this.name = name;
> this.age = age;
> }
> public String getName() {
> return name;
> }
> public void setName(String name) {
> this.name = name;
> }
> public int getAge() {
> return age;
> }
> public void setAge(int age) {
> this.age = age;
> }
> }
>
(5)synchronized和ReentrantLock的比较?
ReentrantLock可以在部分场合替代synchronized,
- (1)可以实现公平锁———进入队列就是公平,非公平就是抢锁是插队抢,
- (2)可以打断上锁的过程,可以使用trylock()或者lockInterruptibly
- (3)锁尚明的队列可以指定任意数量
- (4)可以手动释放锁,lock.unlock.
10.为什么要使用多线程?
先从总体上来说:
- 从计算机底层来说:线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
- 从当代互联网发展趋势来说: 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
再深入到计算机底层来探讨:
- 单核时代: 在单核时代多线程主要是为了提高 CPU 和 IO 设备的综合利用率。举个例子:当只有一个线程的时候会导致 CPU 计算时,IO 设备空闲;进行 IO 操作时,CPU 空闲。我们可以简单地说这两者的利用率目前都是 50%左右。但是当有两个线程的时候就不一样了,当一个线程执行 CPU 计算时,另外一个线程可以进行 IO 操作,这样两个的利用率就可以在理想情况下达到 100%了。
- 多核时代: 多核时代多线程主要是为了提高 CPU 利用率。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,CPU 只会一个 CPU 核心被利用到,而创建多个线程就可以让多个 CPU 核心被利用到,这样就提高了 CPU 的利用率。
11.上下文切换?
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换会这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
12.synchronized 关键字
是什么?(一句话介绍)———>用来做什么?(作用对象)———>实现的原理是什么?(synchronized内存语义,锁状态及其转化)
(1)说一说对synchronized关键字?
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。且为非公平锁。 另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。
庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
(1)synchronized 同步语句块的情况?
synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权。当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
(2)synchronized 修饰方法的的情况
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
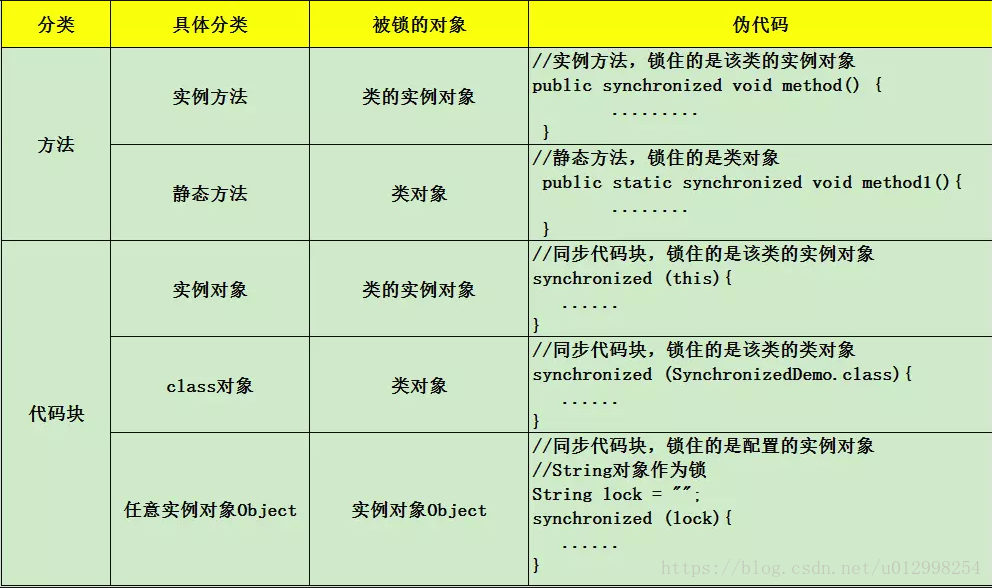
(2)优化
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
| 编号 | 名字 | 解释 |
|---|---|---|
| 1 | 偏向锁 | 引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。 但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉 |
| 2 | 轻量级锁 | 轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。 |
| 3 | 自旋锁和自适应自旋 | 轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。 对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了。 |
| 4 | 锁消除 | 锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。 |
| 5 | 锁粗化 | 原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,——直在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。 |
(3)sychronized C++实现源码
Synchronized 本质是对一个对象监视器(monitor)进行获取:在Java虚拟机执行到monitorenter指令时,(1)首先它会尝试获取对象的锁,如果该对象没有锁,或者当前线程已经拥有了这个对象的锁时,它会把计数器+1;然后当执行到monitorexit 指令时就会将计数器-1;然后当计数器为0时,锁就释放了。(2)如果获取锁 失败,那么当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
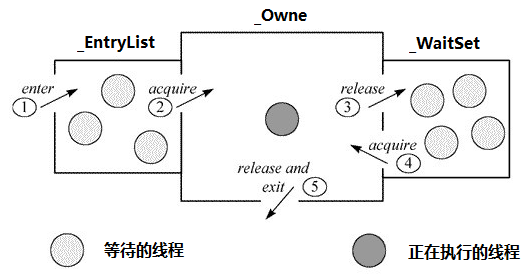
1 | // monitor |
当多个线程同时访问一段同步代码时,首先会进入 _EntryList 队列中,当某个线程获取到对象的 monitor 后进入 _Owner 区域并把 monitor 中的 _owner 变量设置为当前线程,同时 monitor 中的计数器 _count 加 1。即获得对象锁。
若持有 monitor 的线程调用 wait() 方法,将释放当前持有的 monitor,_owner 变量恢复为 null,_count 自减 1,同时该线程进入 _WaitSet 集合中等待被唤醒(等待 synchronized 锁的线程不可被中断,即使调用了该线程的 interrupt 方法。只有获取到锁之后才会中断。另外中断操作只是给线程一个标记,最终执行是看线程本身的状态)。
(4)openjdk官方文档jdk wiki
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
The following figure shows the layout of the header word and the representation of different object states.
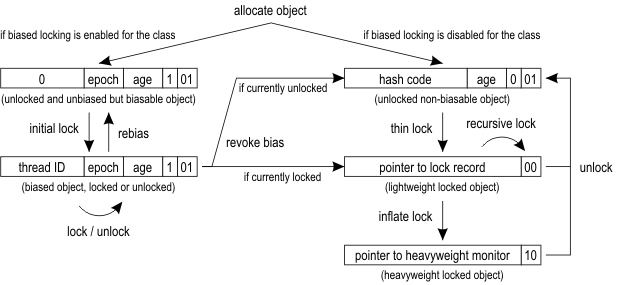
不同的锁状态
12. CAS
(1)ABA问题
- 版本号解决,或者直接加一个Boolean类的标记
- 初看ABA问题像是没有什么问题?但是对于引用类型来说就有问题了,比如B线程修改了属性。
(2)比较和操作的原子性
(3) CAS一直在消耗CPU
一直在转圈,比如竞争就几个,循环OK。
(4)CAS和synchronized的效率
- 不同的场景效率不一样
- synchronized有排序,但是涉及到cpu的一些列操作
12. UNSAFE
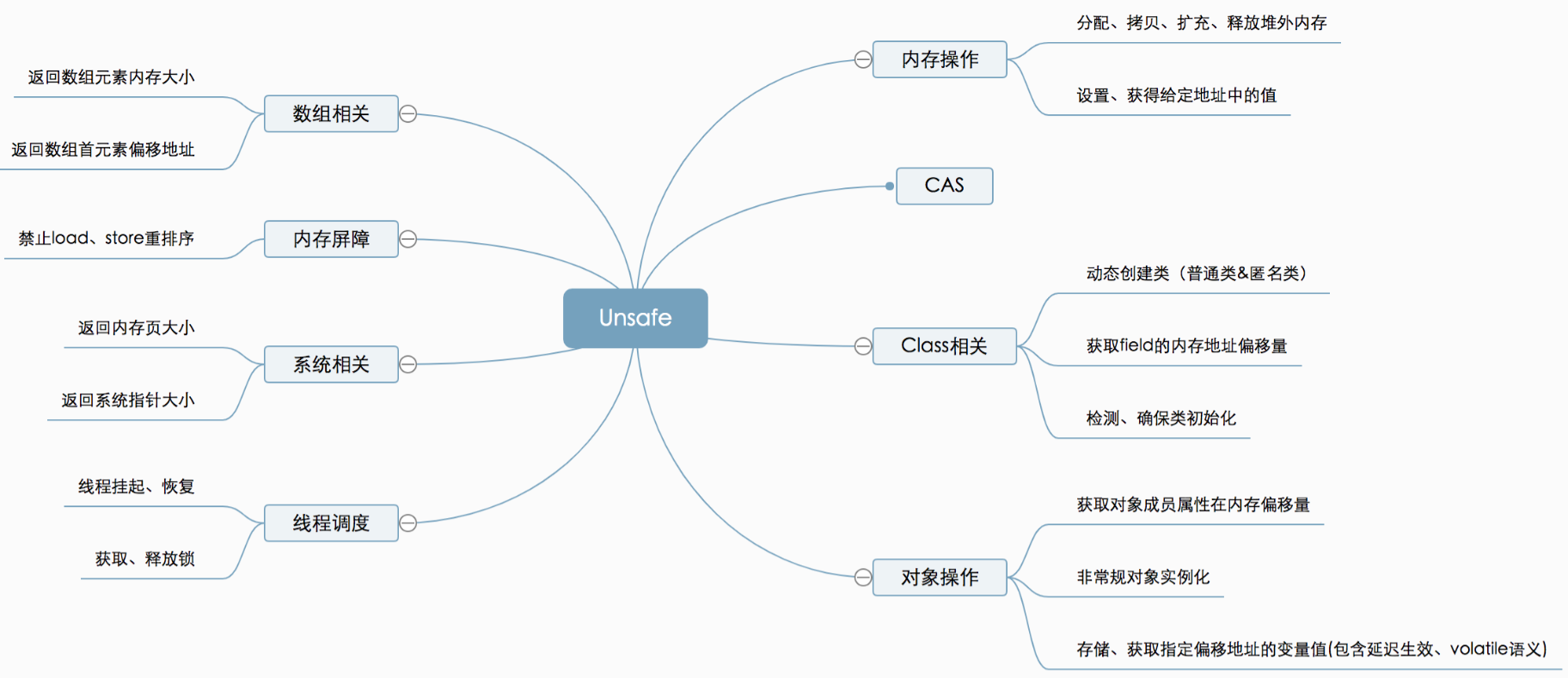
Unsafe提供的API大致可分为内存操作、CAS、Class相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类。
- compareAndSwapInt
AutomicInteger—->unsafe.getAndAddInt—->compareAndSwapInt—->(native)compareAndSwapInt—->unsafe.cpp—->Unsafe_CompareAndSwapInt——>Atomic::cmpxchg—->asm的汇编代码lock comxchg,(comxchg汇编语句不保证原子性,lock指令支持锁总线)
13.AQS原理分析(AbstractQueuedSynchronizer)
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
ReentrangLock、Semaphore,它们的实现都用到了一个共同的基类—AbstractQueuedSynchronizer,简称AQS。
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
AQS相当于CAS+volatile.
14.AQS组件
- Semaphore(信号量)-允许多个线程同时访问:** synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
- CountDownLatch (倒计时器): CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
- CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
编号 CountDownLatch CyclicBarrier 1 减数方式 加数方式 2 countDown函数+await函数 await函数 3 计数为0以后,无法重置 计数达到指定的值后,从0重新开始 4 不可重复利用 可以重复利用
15.AQS对于资源的共享方式
- Exclusive(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
- Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
16.自定义同步器时需要重写下面几个AQS提供的模板方法
1 | isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。 |
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现
tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
17.Future和FutureTask的区别?(Future等结果,FutureTask可以被提交)
线程的创建方式中有两种,一种是实现Runnable接口,另一种是继承Thread,但是这两种方式都有个缺点,那就是在任务执行完成之后无法获取返回结果,于是就有了Callable接口,Future接口与FutureTask类的配和取得返回的结果。FutureTask除了实现了Future接口外还实现了Runnable接口,Future
接口是用来获取异步计算结果的.无论是Runnable接口的实现类还是Callable接口的实现类,都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行 Future模式是Java多线程设计模式中的一种常见模式,它的主要作用就是异步地执行任务,并在需要的时候获取结果。我们知道,一般调用一个函数,需要等待函数执行完成,调用线程才会继续往下执行,如果是一些计算密集型任务,需要等待的时间可能就会比较长。
2
3
> <T> Future<T> submit(Runnable task, T result);
>
2
3
4
5
6
7
8
9
> ExecutorService es = Executors.newSingleThreadExecutor();
>//创建Callable对象任务
> CallableDemo calTask=new CallableDemo();
>//提交任务并获取执行结果
> Future<Integer> future =es.submit(calTask);
>//关闭线程池
> es.shutdown();
>
2
3
4
5
6
7
8
9
10
11
> ExecutorService es = Executors.newSingleThreadExecutor();
> //创建Callable对象任务
> CallableDemo calTask=new CallableDemo();
> //创建FutureTask
> FutureTask<Integer> futureTask=new FutureTask<>(calTask);
> //执行任务
> es.submit(futureTask);
> //关闭线程池
> es.shutdown();
>
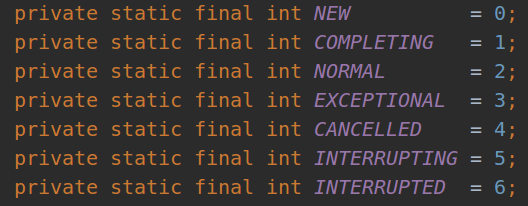
18.FutureTask的7种状态
FutureTask的字段定义非常简单,State标识任务的当前状态,状态之间的转换通过Unsafe来操作,所有操作都基于自旋+CAS完成:
编号 状态 解释 1 new 表示任务的初始化状态; 2 canceled 表示任务还没开始执行就被取消(非中断方式),属于最终状态; 3 interrupting 表示任务还没开始执行就被取消(中断方式),正式被中断前的过渡状态,属于中间状态; 4 interrupted 表示任务还没开始执行就被取消(中断方式),且已被中断,属于最终状态。 5 completing 表示任务已执行完成(正常完成或异常完成),但任务结果或异常原因还未设置完成,属于中间状态; 6 exceptional 表示任务已经执行完成(异常完成),且任务异常已设置完成,属于最终状态; 7 normal 表示任务已经执行完成(正常完成),且任务结果已设置完成,属于最终状态;
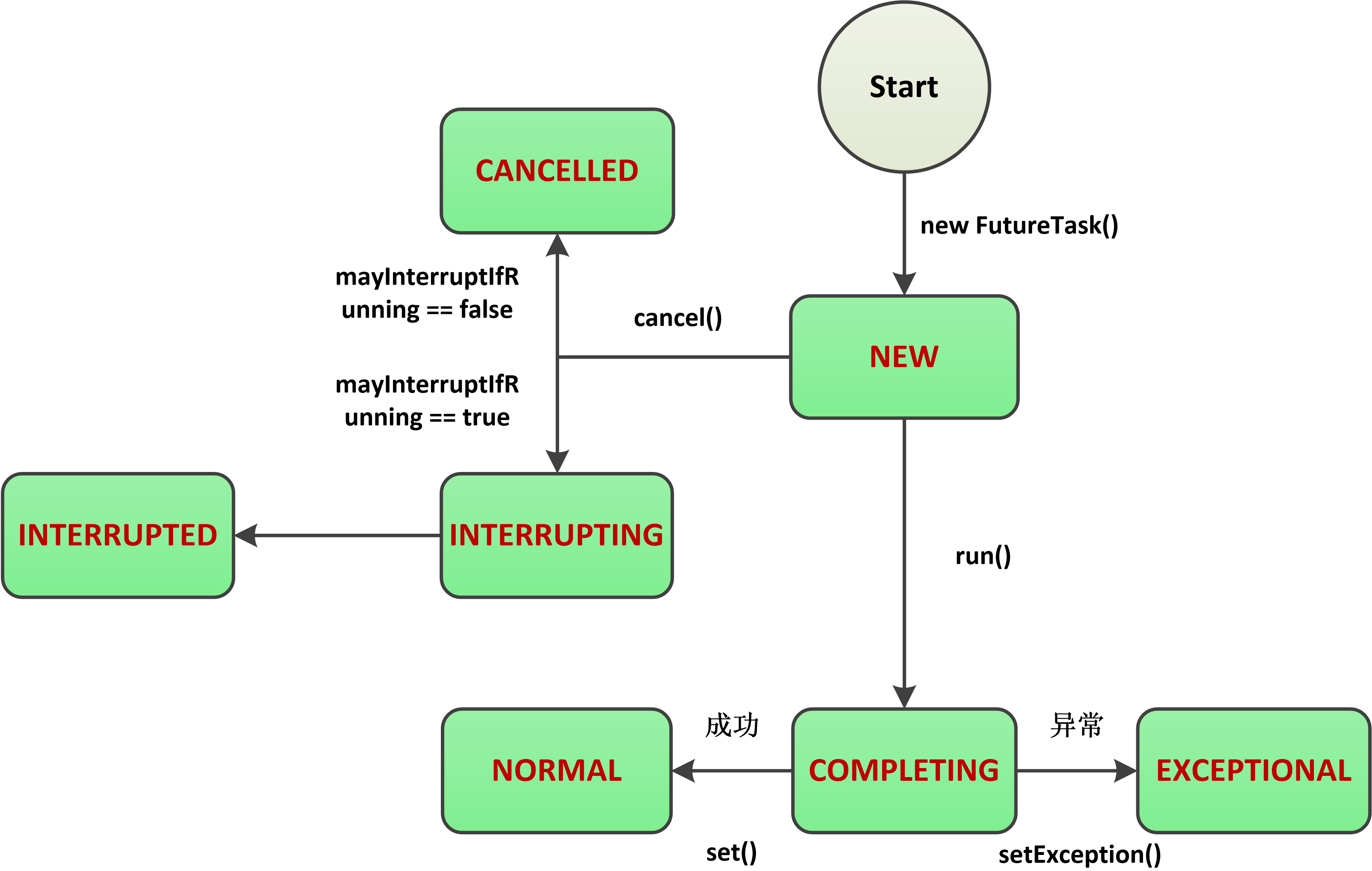
19.Java中的锁
(1)乐观锁,悲观锁
| 编号 | 类别 | 解释 | 实现机制 |
|---|---|---|---|
| 1 | 悲观锁 | 总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。 |
乐观锁一般会使用版本号机制或CAS算法实现。(提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略) |
| 2 | 乐观锁 | 总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。 |
CAS的问题?
- ABA 问题
- 循环时间长开销大
- 只能保证一个共享变量的原子操作
(2)condition实现的原理?
20.线程同步和互斥
- 互斥是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
- 同步是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
- 同步其实已经实现了互斥,所以同步是一种更为复杂的互斥。
- 互斥是一种特殊的同步。
21.Java如何实现原子操作?
在Java中可以通过锁和循环CAS的方式来实现原子操作。
22.Java中AutomicInteger如何实现的?
总结一下,AtomicInteger 中主要实现了整型的原子操作,防止并发情况下出现异常结果,其内部主要依靠JDK 中的unsafe 类操作内存中的数据来实现的。volatile 修饰符保证了value在内存中其他线程可以看到其值得改变。CAS操作保证了AtomicInteger 可以安全的修改value 的值。
23.HashMap为何可能出现环?
24.为什么要使用线程池?
- b降低资源消耗。 通过重复利⽤已创建的线程降低线程创建和销毁造成的消耗。
- 提⾼响应速度。 当任务到达时,任务可以不需要的等到线程创建就能⽴即执⾏。
- 提⾼线程的可管理性。 线程是稀缺资源,如果⽆限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使⽤线程池可以进⾏统⼀的分配,调优和监控.
1 | /** |
25.如何线程安全的实现一个计数器?
26.volatile关键字?
参考:volatile: http://ifeve.com/volatile/
Java语言规范第三版中对volatile的定义如下: java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁更加方便。如果一个字段被声明成volatile,java线程内存模型确保所有线程看到这个变量的值是一致的。Volatile变量修饰符如果使用恰当的话,它比synchronized的使用和执行成本会更低,因为它不会引起线程上下文的切换和调度。
- Java内存模型
- 内存屏障
27. Thread 类中的start() 和 run() 方法有什么区别?
start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,这和直接调用run()方法的效果不一样。
当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程。
创建线程的方式:
方式1:继承Java.lang.Thread类,并覆盖run() 方法。
优势:编写简单;
劣势:单继承的限制——无法继承其它父类,同时不能实现资源共享。方式2:实现Java.lang.Runnable接口,并实现run()方法。
优势:可继承其它类,多线程可共享同一个Thread对象;
劣势:编程方式稍微复杂,如需访问当前线程,需调用Thread.currentThread()方法
28. 线程池大小
- 计算密集型:为什么是核心数+1?对于计算密集型的任务,在拥有N个处理器的系统上,当线程池的大小为N+1时,通常能实现最优的效率。(即使当计算密集型的线程偶尔由于缺失故障或者其他原因而暂停时,这个额外的线程也能确保CPU的时钟周期不会被浪费。)
- IO密集型:核心数*2
29. 什么是可重入锁?实现的原理是什么?
是什么:当一个线程需要获取一个被其他线程锁持有的独占锁的时候,会被阻塞。当一个线程需要获取到自己已经持有的锁的时候是否也会被阻塞呢?如果不被阻塞,那么我们说这个锁是可以重入的,也就是说这个线程获取了这个锁就可以无限次(严格来说是有限次)进入被锁定的代码。
实现的原理:可重入锁实现的原理就是内部维护一个线程标识,使用这个标识来确定当前的锁被哪一个线程占用,然后还需要关联一个计数器。一开始,这个计数器为0,说明这个锁没有被任何线程占用。当一个线程获取到这个锁的时候,计数器的值将会加一,其他线程过来的时候发现持有锁的线程不是自己而被阻塞。如果发现是自己,计数器将会被加一,当释放计数器的时候减一,当计数器为零的时候,锁里面的线程标识重置为null。
30. 生产者和消费者问题?
生产者生产满了就阻塞,消费者消费完了就阻塞,notify和notifyAll是如何实现的?
使用Condition去唤醒不同的队列?
31. ABCABC问题
使用Condition
1 | public class Tset{ |
ps: t.start()会导致run()方法被调用,run()方法中的内容称为线程体,它就是这个线程需要执行的工作。
用start()来启动线程,实现了真正意义上的启动线程,此时会出现异步执行的效果,即在线程的创建和启动中所述的随机性。而如果使用run()来启动线程,就不是异步执行了,而是同步执行,不会达到使用线程的意义.
32. 有多个任务,一个执行错误,其他都取消(分布式事务)
33. ReentrantLock
33.0 重点
(1)类图,(2)state, (3)子类实现,(4)ConditionObject
lock()——->compareAndSetState——>setExclusiveOwnerThread
———>acquire———>tryAcquire———>acquireQueued(这个方法里有死循环)
lock锁缓存行
33.1 如何实现互斥的?
使用cas操作state.
33.2 如何和实现重入的?
使用cas操作AQS的state,如果是当前锁的持有者,state会增加,表示重入的次数,如果哦不是当前线程的持有者,当前线程会被挂起放入到AQS队列中阻塞。
33.3阻塞队列是不是公平的?
34. Disruptor
- 环形队列
35. Condition
- 使用condition的步骤:lock.newCondition创建condition对象,获取锁,然后调用condition的方法
- 一个ReentrantLock支持多个condition对象
- void await() throws InterruptedException;方法会释放锁,让当前线程等待,支持唤醒,支持线程中断
- void awaitUninterruptibly();方法会释放锁,让当前线程等待,支持唤醒,不支持线程中断
- long awaitNanos(long nanosTimeout) throws InterruptedException;参数为纳秒,此方法会释放锁,让当前线程等待,支持唤醒,支持中断。超时之后返回的,结果为负数;超时之前返回的,结果为正数(表示返回时距离超时时间相差的纳秒数)
- boolean await(long time, TimeUnit unit) throws InterruptedException;方法会释放锁,让当前线程等待,支持唤醒,支持中断。超时之后返回的,结果为false;超时之前返回的,结果为true
- boolean awaitUntil(Date deadline) throws InterruptedException;参数表示超时的截止时间点,方法会释放锁,让当前线程等待,支持唤醒,支持中断。超时之后返回的,结果为false;超时之前返回的,结果为true
- void signal();会唤醒一个等待中的线程,然后被唤醒的线程会被加入同步队列,去尝试获取锁
- void signalAll();会唤醒所有等待中的线程,将所有等待中的线程加入同步队列,然后去尝试获取锁
36. LockSupport类介绍
36.1 原理
LockSupport类可以阻塞当前线程以及唤醒指定被阻塞的线程。主要是通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作的。
每个线程都有一个许可(permit),permit只有两个值1和0,默认是0。
- 当调用unpark(thread)方法,就会将thread线程的许可permit设置成1(注意多次调用unpark方法,不会累加,permit值还是1**)。
- 当调用park()方法,如果当前线程的permit是1,那么将permit设置为0,并立即返回。如果当前线程的permit是0,那么当前线程就会阻塞,直到别的线程将当前线程的permit设置为1时,park方法会被唤醒,然后会将permit再次设置为0,并返回。
注意:因为permit默认是0,所以一开始调用park()方法,线程必定会被阻塞。调用unpark(thread)方法后,会自动唤醒thread线程,即park方法立即返回。
36.2 LockSupport中常用的方法
阻塞线程
• void park():阻塞当前线程,如果调用unpark**方法或者当前线程被中断**,从能从park()方法中返回
• void park(Object blocker):功能同方法1,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查
• void parkNanos(long nanos):阻塞当前线程,最长不超过nanos纳秒,增加了超时返回的特性
• void parkNanos(Object blocker, long nanos):功能同方法3,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查
• void parkUntil(long deadline):阻塞当前线程,直到deadline,deadline是一个绝对时间,表示某个时间的毫秒格式
• void parkUntil(Object blocker, long deadline):功能同方法5,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
唤醒线程
• void unpark(Thread thread):唤醒处于阻塞状态的指定线程
37.线程唤醒的方法
- 方式1:Object中的wait、notify、notifyAll方法
- 方式2:juc中Condition接口提供的await、signal、signalAll方法
- 方式3:juc中的LockSupport提供的park、unpark方法
3种方式对比:
| Object | Condtion | LockSupport | |
|---|---|---|---|
| 前置条件 | 需要在synchronized中运行 | 需要先获取Lock的锁 | 无 |
| 无限等待 | 支持 | 支持 | 支持 |
| 超时等待 | 支持 | 支持 | 支持 |
| 等待到将来某个时间返回 | 不支持 | 支持 | 支持 |
| 等待状态中释放锁 | 会释放 | 会释放 | 不会释放 |
| 唤醒方法先于等待方法执行,能否唤醒线程 | 否 | 否 | 可以 |
| 是否能响应线程中断 | 是 | 是 | 是 |
| 线程中断是否会清除中断标志 | 是 | 是 | 否 |
| 是否支持等待状态中不响应中断 | 不支持 | 支持 | 不支持 |
38. 并发队列

线程池阻塞队列的设置:
- 无界队列
队列大小无限制,常用的为无界的LinkedBlockingQueue,使用该队列做为阻塞队列时要尤其当心,当任务耗时较长时可能会导致大量新任务在队列中堆积最终导致OOM。阅读代码发现,Executors.newFixedThreadPool 采用就是 LinkedBlockingQueue,而楼主踩到的就是这个坑,当QPS很高,发送数据很大,大量的任务被添加到这个无界LinkedBlockingQueue 中,导致cpu和内存飙升服务器挂掉。
- 有界队列
常用的有两类,一类是遵循FIFO原则的队列如ArrayBlockingQueue,另一类是优先级队列如PriorityBlockingQueue。PriorityBlockingQueue中的优先级由任务的Comparator决定。
使用有界队列时队列大小需和线程池大小互相配合,线程池较小有界队列较大时可减少内存消耗,降低cpu使用率和上下文切换,但是可能会限制系统吞吐量。
在我们的修复方案中,选择的就是这个类型的队列,虽然会有部分任务被丢失,但是我们线上是排序日志搜集任务,所以对部分对丢失是可以容忍的。
- 同步移交队列
如果不希望任务在队列中等待而是希望将任务直接移交给工作线程,可使用SynchronousQueue作为等待队列。SynchronousQueue不是一个真正的队列,而是一种线程之间移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接收这个元素。只有在使用无界线程池或者有饱和策略时才建议使用该队列。
Summary of BlockingQueue methods
| Throws exception | Special value | Blocks | Times out | |
|---|---|---|---|---|
| Insert | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| Remove | remove() | poll() | take() | poll(time, unit) |
| Examine | element() | peek() | not applicable | not applicable |
(四)JVM
1.虚拟机的参数
| 编号 | 参数 | 含义 |
|---|---|---|
| 1 | -XX:PrintFlagsInitial | 打印默认的配置信息 |
| 2 | -Xms8m | 堆空间8m |
| 3 | -Xmx8x | 堆空间最大8m |
| 4 | ||
| 5 | -XX:MaxDirectMemorySize=5m | 最大直接内存5m |
| 6 | -XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=8m | 指定元空间的大小8m |
| 7 | -XX:MaxTenuringThreshold | 对象晋升到老年代的年龄阈值 |
| 8 | -XX:PreBlockSpin | 自旋次数的默认值是10次 |
2.JVM内存区域(运行时数据区)
| 编号 | 名字 | 功能 | 备注 |
|---|---|---|---|
| 1 | 堆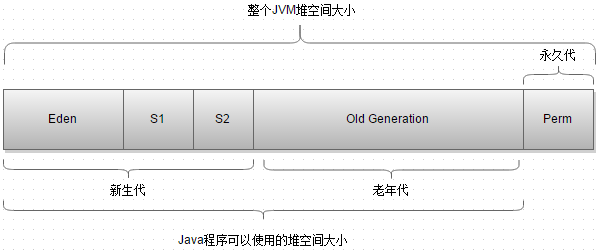 |
主要用于存放新创建的对象 (所有对象都在这里分配内存) | jdk1.8之后永久代被替换成为了元空间(Metaspace) |
| 2 | 方法区 | 被虚拟机加载的类信息(版本、字段、方法、接口)、常量、静态变量、即时编译器编译后的代码等数据(加常静即) | 运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)方法中的基本类型本地变量将直接存储在工作内存的栈帧结构中; |
| 3 | 虚拟机栈(线程私有) | 动态链接,方法出口,操作数栈,局部变量表(动方操局) | 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。 |
| 4 | 本地方法栈(线程私有) | 区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。 | |
| 5 | 程序计数器(线程私有) | 程序计数器主要有下面两个作用:(1)字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。在多线程的情况下,(2)程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。 |
堆的细节信息(使用虚拟机参数-XX:+PrintGCDetails)
Heap PSYoungGen total 74752K, used 3871K [0x000000076d180000, 0x0000000772480000, 0x00000007c0000000) eden space 64512K, 6% used [0x000000076d180000,0x000000076d547c70,0x0000000771080000) from space 10240K, 0% used [0x0000000771a80000,0x0000000771a80000,0x0000000772480000) to space 10240K, 0% used [0x0000000771080000,0x0000000771080000,0x0000000771a80000) ParOldGen total 171008K, used 0K [0x00000006c7400000, 0x00000006d1b00000, 0x000000076d180000) object space 171008K, 0% used [0x00000006c7400000,0x00000006c7400000,0x00000006d1b00000) Metaspace used 3009K, capacity 4496K, committed 4864K, reserved 1056768K class space used 330K, capacity 388K, committed 512K, reserved 1048576K
当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.GC 期间虚拟机又发现 allocation1 无法存入 Survivor 空间,所以只好通过 分配担保机制 把新生代的对象提前转移到老年代中去,老年代上的空间足够存放 allocation1,所以不会出现 Full GC。执行 Minor GC 后,后面分配的对象如果能够存在 eden 区的话,还是会在 eden 区分配内存。
3.直接内存也会爆出OutOfMemoryError
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 异常出现。
JDK1.4中新加入的 NIO(New Input/Output) 类,引入了一种基于通道(Channel) 与缓存区(Buffer) 的 I/O 方式,它可以直接使用Native函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。
本机直接内存的分配不会收到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。(demo:修改虚拟机参数,使用allocateDirect方法直接分配直接内存的空间)
4.对象的创建过程?
加分初设执, 双亲委派模型
(1)类加载检查
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
类加载过程(加验准解初)
- 加载 protected Class<?> loadClass(String name, boolean resolve)是线程安全的!
- 通过全类名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的Class 对象,作为方法区这些数据的访问入口
- 验证(文元字符)
- 文件格式验证
- 元数据验证
- 字节码验证
- 符号引用验证
- 准备:准备阶段是正式为类变量分配内存并设置类变量初始值的阶段
- 解析:解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
- 初始化:初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器
<clinit> ()方法的过程。加载器
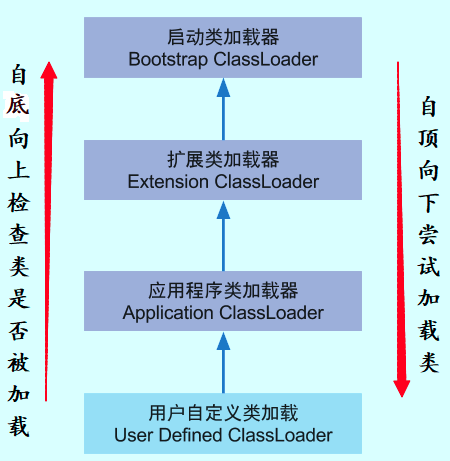
- BootstrapClassLoader(启动类加载器) :最顶层的加载类,由C++实现,负责加载
%JAVA_HOME%/lib目录下的jar包和类或者或被-Xbootclasspath参数指定的路径中的所有类。- ExtensionClassLoader(扩展类加载器) :主要负责加载目录
%JRE_HOME%/lib/ext目录下的jar包和类,或被java.ext.dirs系统变量所指定的路径下的jar包。- AppClassLoader(应用程序类加载器) :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 双亲委派模型 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派该父类加载器的 loadClass() 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 BootstrapClassLoader 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为null时,会使用启动类加载器
BootstrapClassLoader作为父类加载器。
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为
java.lang.Object类的话,那么程序运行的时候,系统就会出现多个不同的Object类。
(2)分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。分配方式有 “指针碰撞” 和 “空闲列表”两种,选择那种分配方式由 Java 堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
(3)初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
(4)设置对象头
(元数据信息,对象的哈希码,对象的GC分代信息)
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
(5)执行init方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
<init>方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行<init>方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
5.JVM常见面试题
(1)如何判断对象是否死亡(两种方法)?
- 引用计数法(和引用有关系)
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
- 可达性分析(和引用有关系)
这个算法的基本思想就是通过一系列的称为GC Roots的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
(2)简单的介绍一下强引用、软引用、弱引用、虚引用
- 强引用
我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空 间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
- 软引用
如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
- 弱引用
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
- 虚引用
与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
(3)如何判断一个常量是废弃常量?
假如在常量池中存在字符串 “abc”,如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 “abc” 就是废弃常量,如果这时发生内存回收的话而且有必要的话,”abc” 就会被系统清理出常量池。
(4)如何判断一个类是无用的类?
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。(双亲委派模型)
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
(5)垃圾收集有哪些算法,各自的特点?
- 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
- 标记清除
该算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
效率问题
空间问题(标记清除后会产生大量不连续的碎片)
- 标记整理
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
- 分代
(6)HotSpot 为什么要分为新生代和老年代?
根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
分代收集算法(HotSpot 虚拟机 GC 采用分代收集算法)
根据对象存活周期的不同,将内存划分为几块。一般是把 Java 堆分为新生代和老年代,根据年代的特点来选择最佳的收集算法。
- 新生代:复制算法
- 老年代:标记-整理算法
堆大小=新生代+老年代(默认分别占堆空间为1/3、2/3),新生代又被分为Eden、from survivor、to survivor(默认8:1:1)
这样划分是为了更好的管理堆内存中的对象,方便 GC 算法来进行垃圾回收。
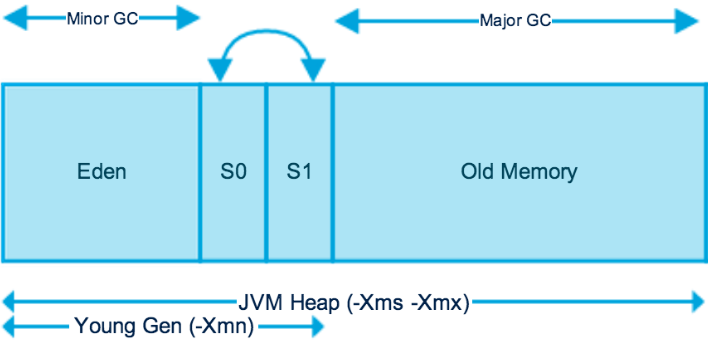
对象的分配通常在 Eden 中(大对象(需要大量连续内存空间的 Java 对象,如很长的字符串或数据)直接进入老年代,-XX:PretenureSizeThreshold)。
当 Eden 区满后,会触发 Minor GC,把 Eden 区和 from survivor 区中存活的对象进行转移,其中到达年龄(经过多次Minor GC)的会被放入老年代,未到达年龄的放入 to survivor 区。
然后清空 Eden 区和 from survivor 区,交换 from survivor 与 to survivor 的名字。
若存活对象大于 to survivor 区容量,则会被直接放入老年代。若打开了自适应(-XX:+AdaptiveSizePolicy),GC会自动重新调整新生代大小。
若老年代满了,则触发 Full GC。
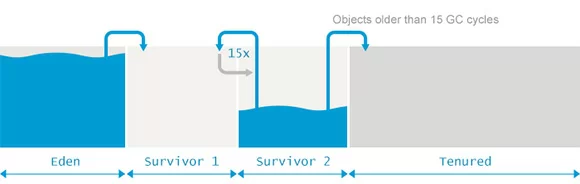
Minor GC vs Major GC/Full GC:
- Minor GC:回收新生代(包括 Eden 和 Survivor 区域),因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
- Major GC / Full GC: 回收老年代,出现了 Major GC,经常会伴随至少一次的 Minor GC,但这并非绝对。Major GC 的速度一般会比 Minor GC 慢 10 倍 以上。
在 JVM 规范中,Major GC 和 Full GC 都没有一个正式的定义,所以有人也简单地认为 Major GC 清理老年代,而 Full GC 清理整个内存堆。
(7)常见的垃圾回收器有那些?
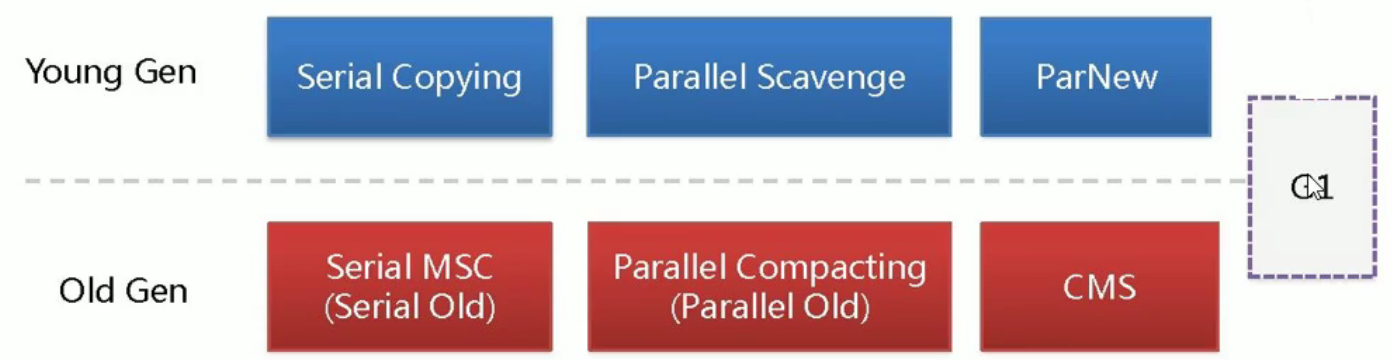
| 编号 | 回收器 | 算法 | 步骤 | 备注 |
|---|---|---|---|---|
| 1 | Serial 收集器(串行) |  |
单CPU的client模式 | |
| 2 | ParNew 收集器(并行) |  |
它是许多运行在Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器配合工作。 | |
| 3 | Parallel Scavenge 收集器(并行) | (吞吐量)Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU),后台运行不需要太多交互 | ||
| 4 | Serial Old 收集器(串行) | 单CPU的client模式,和CMS配合 | ||
| 5 | Parallel Old 收集器(并行) | (吞吐量)后台运行不需要太多交互 | ||
| 6 | CMS 收集器(并发) | 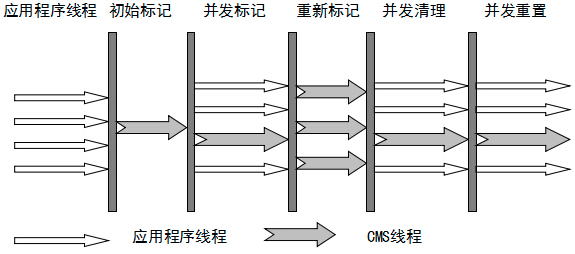 标记清除 |
(1)初始标记 (2)并发标记(混合) (3)重新标记 (4)并发清除(混合) |
CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验),集中使用在互联网或者B/S系统服务端 |
| 7 | G1 收集器(并发) | 面向服务端,将来替换CMS |
(8)Minor Gc 和 Full GC 有什么不同呢?
- 新生代 GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
- 老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
(9)什么时候触发FULL GC?
除直接调用System.gc外,触发Full GC执行的情况有如下四种。
旧生代空间不足旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误: java.lang.OutOfMemoryError: Java heap space 为避免以上两种状况引起的FullGC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
Permanet Generation空间满 PermanetGeneration中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息: java.lang.OutOfMemoryError: PermGen space 为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
CMS GC时出现promotion failed和concurrent mode failure 对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。 promotionfailed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。 应对措施为:增大survivorspace、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX:CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间 这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。 例如程序第一次触发MinorGC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。 当新生代采用PSGC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。 除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java-Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
(10)对象分配规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
- 大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值对象进入老年区。
- 动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
- 空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC。
6.JDK 监控和故障处理工具总结
故障排查:https://www.cnblogs.com/stateis0/p/9062196.html
线上 CPU 飚高问题大家应该都遇到过,那么如何定位问题呢?
思路:首先找到 CPU 飚高的那个 Java 进程,因为你的服务器会有多个 JVM 进程。然后找到那个进程中的 “问题线程”,最后根据线程堆栈信息找到问题代码。最后对代码进行排查,如何操作呢?
- 通过 top 命令找到 CPU 消耗最高的进程,并记住进程 ID。
- 再次通过 top -Hp [进程 ID] 找到 CPU 消耗最高的线程 ID,并记住线程 ID.
- 通过 JDK 提供的 jstack 工具 dump 线程堆栈信息到指定文件中。具体命令:jstack -l [进程 ID] >jstack.log。
- 由于刚刚的线程 ID 是十进制的,而堆栈信息中的线程 ID 是16进制的,因此我们需要将10进制的转换成16进制的,并用这个线程 ID 在堆栈中查找。使用 printf “%x\n” [十进制数字] ,可以将10进制转换成16进制。
- 通过刚刚转换的16进制数字从堆栈信息里找到对应的线程堆栈。就可以从该堆栈中看出端倪。
| 编号 | 工具 | 解释 | 用法 |
|---|---|---|---|
| 1 | jps | (JVM Process Status): 类似 UNIX 的 ps 命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息; |
|
| 2 | jinfo | (Configuration Info for Java) : Configuration Info forJava,显示虚拟机配置信息; | (1)jinfo -flag MaxHeapSize |
| 3 | jstat | (JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据; | |
| 4 | jmap | (Memory Map for Java) :生成堆转储快照; | (1)可以使用-XX:+HeapDumpOnOutOfMemoryError代替 |
| 5 | jhat | (JVM Heap Dump Browser ) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果; | |
| 6 | jstack | (Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。 | |
| 7 | jconsole | ||
| 8 | javap | 查看字节码 |
7.类文件结构(魔文常访当字方属)
| 编号 | 数据 | 解释 |
|---|---|---|
| 1 | 魔数 | 每个 Class 文件的头四个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接收的 Class 文件。 |
| 2 | Class文件版本 | 高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。 |
| 3 | 常量池 | 常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。javap -v *.class查看 |
| 4 | 访问标志 | 在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。 |
| 5 | 当前类索引,父类索引和接口索引集合 | 类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 java.lang.Object 之外,所有的 java 类都有父类,因此除了 java.lang.Object 外,所有 Java 类的父类索引都不为 0。接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按implents(如果这个类本身是接口的话则是extends) 后的接口顺序从左到右排列在接口索引集合中。 |
| 6 | 字段表集合 | 字段表(field info)用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。 |
| 7 | 方法表集合 | Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。 |
| 8 | 属性表集合 | 在 Class 文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。 |
8.常量池存放(字面量,符号引用)
(1)字面量
字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。
(2)符号引用(全限定名,描述符)
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
9.自定义加载器(不要轻易覆盖loadClass)
双亲委派模型是为了保证 如果加载的类是一个系统类,那么会优先由Bootstrap ClassLoader 、Extension ClassLoader先去加载,而不是使用我们自定义的ClassLoader去加载,保证系统的安全!
2
3
> Class<?> depv1Class = v1.loadClass("JavaDemo.VMTest.DiamondDependency.v1.Dep");
>
为什么要自定义ClassLoader?
因为系统的ClassLoader只会加载指定目录下的class文件,如果你想加载自己的class文件,那么就可以自定义一个ClassLoader。而且我们可以根据自己的需求,对class文件进行加密和解密。有很多字节码加密技术就是依靠定制 ClassLoader 来实现的。先使用工具对字节码文件进行加密,运行时使用定制的 ClassLoader 先解密文件内容再加载这些解密后的字节码。
如何自定义ClassLoader?(findClass———>defineClass———>loadClass)
- 新建一个类继承自java.lang.ClassLoader,重写它的findClass方法。
- 将class字节码数组转换为Class类的实例(这点需要和判断一个类是不是没用建立联系)
- 使用:调用loadClass方法即可(这点要和判断一个类是不是没用建立联系)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
>
> import java.io.*;
>
>public class MyClassLoader extends ClassLoader {
> //指定路径
> private String path ;
>
> public MyClassLoader(String classPath){
> path=classPath;
> }
> /**
> * 重写findClass方法
> * @param name 是我们这个类的全路径
> * @return
> * @throws ClassNotFoundException
> */
>
> protected Class<?> findClass(String name) throws ClassNotFoundException {
> Class log = null;
> // 获取该class文件字节码数组
> byte[] classData = getData();
>
> if (classData != null) {
> // 将class的字节码数组转换成Class类的实例
> log = defineClass(name, classData, 0, classData.length);
> }
> return log;
> }
>
> /**
> * 将class文件转化为字节码数组
> * @return
> */
> private byte[] getData() {
> File file = new File(path);
> if (file.exists()){
> FileInputStream in = null;
> ByteArrayOutputStream out = null;
> try {
> in = new FileInputStream(file);
> out = new ByteArrayOutputStream();
>
> byte[] buffer = new byte[1024];
> int size = 0;
> while ((size = in.read(buffer)) != -1) {
> out.write(buffer, 0, size);
> }
>
> } catch (IOException e) {
> e.printStackTrace();
> } finally {
> try {
> in.close();
> } catch (IOException e) {
> e.printStackTrace();
> }
> }
> return out.toByteArray();
> }else{
> return null;
> }
> }
> }
>
2
3
4
5
6
7
8
>
> public class Log {
> public static void main(String[] args) {
> System.out.println("load Log class successfully");
> }
> }
>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
>
>import java.lang.reflect.InvocationTargetException;
> import java.lang.reflect.Method;
>
> public class ClassLoaderMain {
> public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException, NoSuchMethodException, SecurityException, IllegalArgumentException, InvocationTargetException, InvocationTargetException {
> //这个类class的路径
> String classPath = "/home/mao/workspace/java/out/production/java/JavaDemo/VMTest/ClassLoaderDemo/Log.class";
>
> MyClassLoader myClassLoader = new MyClassLoader(classPath);
>
> //类的全称
> String packageNamePath = "JavaDemo.VMTest.ClassLoaderDemo.Log";
> //加载Log这个class文件
> Class<?> Log = myClassLoader.loadClass(packageNamePath);
>
> System.out.println("类加载器是:" + Log.getClassLoader());
>
> //利用反射获取main方法
> Method method = Log.getDeclaredMethod("main", String[].class);
> Object object = Log.newInstance();
> String[] arg = {"ad"};
> method.invoke(object, (Object) arg);
> }
> }
>
>
10.钻石依赖问题
项目管理上有一个著名的概念叫着「钻石依赖」,是指软件依赖导致同一个软件包的两个版本需要共存而不能冲突。ClassLoader固然可以解决依赖冲突问题,不过它也限制了不同软件包的操作界面必须使用反射或接口的方式进行动态调用。
1 | package JavaDemo.VMTest.DiamondDependency.v1; |
1 | package JavaDemo.VMTest.DiamondDependency.v2; |
1 | package JavaDemo.VMTest.DiamondDependency; |
11.JMM
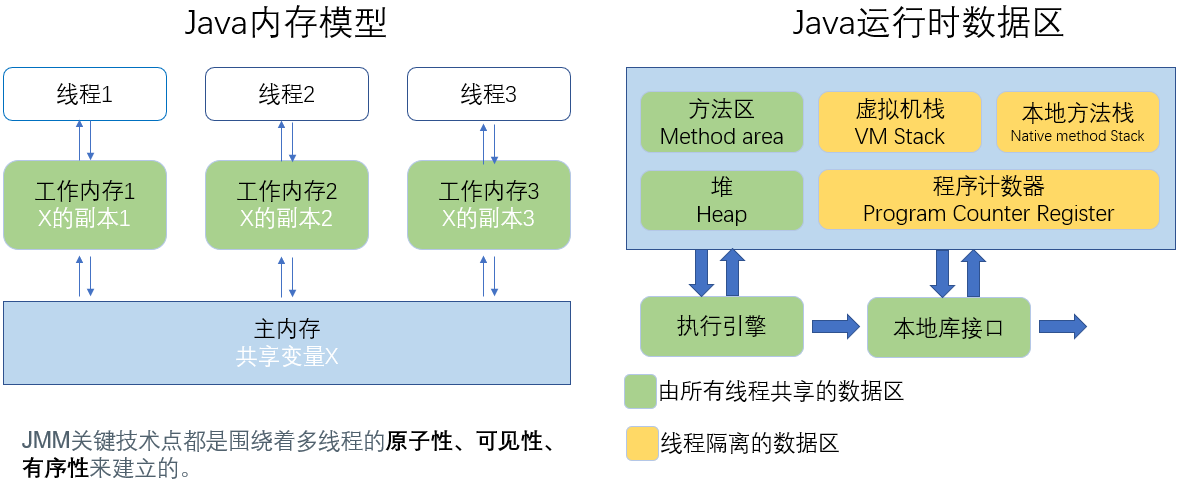
Java内存模型简称JMM(Java Memory Model),是Java虚拟机所定义的一种抽象规范,用来屏蔽不同硬件和操作系统的内存访问差异,让java程序在各种平台下都能达到一致的内存访问效果。
具体说来,JVM中存在一个主存区(Main Memory或Java Heap Memory),对于所有线程进行共享,而每个线程又有自己的工作内存(Working Memory,实际上是一个虚拟的概念),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作并非发生在主存区,而是发生在工作内存中,而线程之间是不能直接相互访问的,变量在程序中的传递,是依赖主存来完成的。
JMM描述的是一组规则,围绕原子性、有序性和可见性展开;
线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。
操作:
- lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占的状态。
- unclock(解锁):作用于主内存的变量,把一个处于锁定的状态释放出来。
- read(读取):作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中
- load(载入):作用于工作内存的变量,把read操作从主内存 得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的 值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,把一个从执行引擎接收到的值 赋值给工作内存的变量,每当虚拟机遇到一个给变 量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传递到主内存,以便write操作使用。
- write(写入):作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中。
12.内存模型三大特性
(1)原子性
Java 内存模型保证了 read、write、load、use、assign、store、lock 和 unlock 操作具有原子性
(2)可见性
可见性指当一个线程修改了共享变量的值,其它线程能够立即得知这个修改。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值来实现可见性的。JMM 内部的实现通常是依赖于所谓的内存屏障,通过禁止某些重排序的方式,提供内存可见性保证,也就是实现了各种 happen-before 规则。与此同时,更多复杂度在于,需要尽量确保各种编译器、各种体系结构的处理器,都能够提供一致的行为。
(3)有序性
有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
13.先行发生原则(Happen-Before)(可见性保证)
由于指令重排序的存在,两个操作之间有happen-before关系,并不意味着前一个操作必须要在后一个操作之前执行。仅仅要求前一个操作的执行结果对于后一个操作是可见的,并且前一个操作按顺序排在第二个操作之前. 内存模型使用先行发生原则在Java内存模型中保证多线程操作可见性的机制
| 编号 | 规则 | 解释 |
|---|---|---|
| 1 | 单一线程原则(程序员顺序规则) | 在一个线程内,在程序前面的操作先行发生于后面的操作。 |
| 2 | 管程锁定规则(监视器锁规则) | 一个 unlock(解锁) 操作先行发生于后面对同一个锁的 lock(加锁) 操作。 |
| 3 | volatile 变量规则 | 对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。 |
| 4 | 线程启动规则 | Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。 |
| 5 | 线程加入规则 | Thread 对象的结束先行发生于 join() 方法返回。 |
| 6 | 线程中断规则 | 对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。 |
| 7 | 对象终结规则 | 一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。 |
| 8 | 传递性 | 如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。 |
14. 一个Main方法执行的过程?
15. JVM调优命令
Sun JDK监控和故障处理命令有jps、jstat、jmap、jhat、jstack、jinfo.
- jps,JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat,JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap,JVM Memory Map命令用于生成heap dump文件
- jhat,JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看
- jstack,用于生成java虚拟机当前时刻的线程快照。
- jinfo,JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数。
(五)I/O
资料(http://wiki.jikexueyuan.com/project/java-nio-zh/java-nio-tutorial.html)
1.InputStream,OutputStream,Reader,Writer?
- InputStream,OutputStream:面向字节流
- Reader,Writer:面向字符流
| 操作对象 | 文件,数组,基本数据类型,缓冲,管道,打印,对象序列化,转化 |
|---|---|
| (1)文件 | FileInputStream FileOutputStream FileReader FileWriter |
| (2)数组 | ByteArrayInputStream ByteArrayOutputStream CharArrayReader CharArrayWriter |
| (3)基本数据类型 | DataInputStream DataOutputStream |
| (4)缓冲 | BufferedInputStream BufferedOutputStream BufferedReader BufferedWriter |
| (5)管道 | PipedInputStream PipedOutputStream PipedReader PipedWriter |
| (6)打印 | printStream printWriter |
| (7)对象序列化 | ObjectInputStream ObjectOutputStream |
| (8)转化 | InputStreamReader OutputStreamWriter |
2.I/O相关的概念(如同步/异步,阻塞/非阻塞)
(1)I/O分类
- java 中 IO 流分为几种?
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流。
- Java Io流共涉及40多个类, Java I0流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
(2)同步/异步,阻塞/非阻塞
同步/异步(被调用者不会/会直接返回结果)
阻塞/非阻塞(调用者不会/会去做其他的事情,需不需要一直等)
3.Java NIO和IO之间的区别
IO是面向流的,NIO是面向缓冲区的.
| IO | NIO |
|---|---|
| IO流是阻塞的 | NIO流是不阻塞的 |
| IO 面向流(Stream oriented) | NIO 面向缓冲区(Buffer oriented) |
| NIO 通过Channel(通道) 进行读写。 | |
| NIO有选择器,选择器用于使用单个线程处理多个通道。 |
(1)面向流和面向缓冲区比较(Stream Oriented vs. Buffer Oriented)
第一个重大差异是IO是面向流的,而NIO是面向缓存区的。这句话是什么意思呢?
Java IO面向流意思是我们每次从流当中读取一个或多个字节。怎么处理读取到的字节是我们自己的事情。他们不会再任何地方缓存。再有就是我们不能在流数据中向前后移动。如果需要向前后移动读取位置,那么我们需要首先为它创建一个缓存区。socket.getOutputStream().write(), InputStream inputStream = socket.getInputStream(); inputStream.read(data)) 这里data可以被指定为一个数组
Java NIO是面向缓冲区的,这有些细微差异。数据是被读取到缓存当中以便后续加工。我们可以在缓存中向向后移动。这个特性给我们处理数据提供了更大的弹性空间。当然我们任然需要在使用数据前检查缓存中是否包含我们需要的所有数据。另外需要确保在往缓存中写入数据时避免覆盖了已经写入但是还未被处理的数据。
(2)阻塞和非阻塞IO比较(Blocking vs. No-blocking IO)
Java IO的各种流都是阻塞的。这意味着一个线程一旦调用了read(),write()方法,那么该线程就被阻塞住了,知道读取到数据或者数据完整写入了。在此期间线程不能做其他任何事情。
Java NIO的非阻塞模式使得线程可以通过channel来读数据,并且是返回当前已有的数据,或者什么都不返回如果但钱没有数据可读的话。这样一来线程不会被阻塞住,它可以继续向下执行。 NIO提供了与传统BIO模型中的 Socket和 ServerSocket相对应的 SocketChannel和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。
通常线程在调用非阻塞操作后,会通知处理其他channel上的IO操作。因此一个线程可以管理多个channel的输入输出。
4.NIO和AIO的对比?
- NIO是同步非阻塞的,AIO是异步非阻塞的
- 由于NIO的读写过程依然在应用线程里完成,所以对于那些读写过程时间长的,NIO就不太适合。而AIO的读写过程完成后才被通知,所以AIO能够胜任那些重量级,读写过程长的任务。
NIO:http://wiki.jikexueyuan.com/project/java-nio-zh/java-nio-non-blocking-server.html
5.Channel,Buffer,Seletor?
| Channel | Buffer | Selector |
|---|---|---|
| FileChannel DatagramChannel SocketChannel ServerSocketChannel |
7种基本类型+MappedBytesBuffer (1) ByteBuffer (2) CharBuffer (3) DoubleBuffer (4) FloatBuffer (5) IntBuffer (6) LongBuffer (7) ShortBuffer |
 |
(1)Channel
- FileChanel
1 | RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw"); |
在Java NIO中如果一个channel是FileChannel类型的,那么他可以直接把数据传输到另一个channel。逐个特性得益于FileChannel包含的transferTo和transferFrom两个方法。
1 | RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw"); |
1 | RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw"); |
- SocketChannel
在Java NIO体系中,SocketChannel是用于TCP网络连接的套接字接口,相当于Java网络编程中的Socket套接字接口。创建SocketChannel主要有两种方式,如下:
| 打开一个SocketChannel并连接网络上的一台服务器。 |
|---|
| 当ServerSocketChannel接收到一个连接请求时,会创建一个SocketChannel。 |
在Java NIO中,ServerSocketChannel是用于监听TCP链接请求的通道,正如Java网络编程中的ServerSocket一样。ServerSocketChannel实现类位于java.nio.channels包下面。
1 | // 打开ServerSocketChannel |
(2)Buffer
Java NIO Buffers用于和NIO Channel交互。我们从channel中读取数据到buffers里,从buffer把数据写入到channels. buffer本质上就是一块内存区,可以用来写入数据,并在稍后读取出来。这块内存被NIO Buffer包裹起来,对外提供一系列的读写方便开发的接口。
利用Buffer读写数据,通常遵循四个步骤:
把数据写入buffer;
调用flip;
从Buffer中读取数据;
调用buffer.clear()或者buffer.compact()
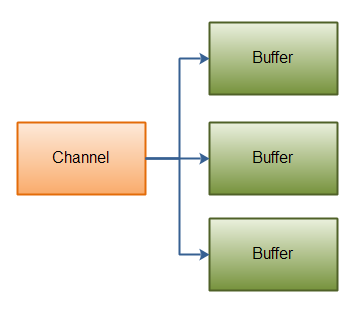
Java NIO发布时内置了对scatter / gather的支持。scatter / gather是通过通道读写数据的两个概念。
|
 |
| 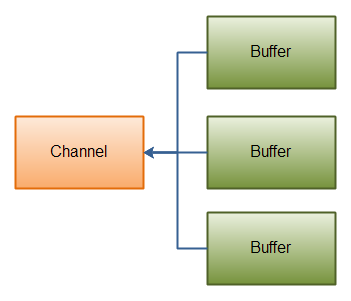 |
|
| :————————————-: | :————————————: |
| Scatter | Gather |
(3)Selector
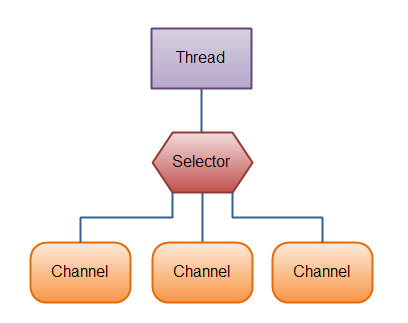
Selector是Java NIO中的一个组件,用于检查一个或多个NIO Channel的状态是否处于可读、可写。如此可以实现单线程管理多个channels,也就是可以管理多个网络链接。
1 | // 创建Selector |
6.Java NIO Channel通道和流的区别
- 通道可以读也可以写,流一般来说是单向的(只能读或者写)。
- 通道可以异步读写。
- 通道总是基于缓冲区Buffer来读写。
7.SocketChannel , ServerSocketChannel
| SocketChannel | ServerSocketChannel | |
|---|---|---|
| 方法 | open(); close(); write(); read(); connect(); | open(); close(); accept(); |
8.AsynchronousChannel(提前返回)
(1)read
- 第一种方式(使用CompletionHandler)

- 第二种方式(使用Future)

(2)write
- 第一种方式(使用CompletionHandler)

- 第二种方式(使用Future)

9.什么是Java序列化,如何实现Java序列化?
(1)含义:(扯一点Python相关)
序列化:把对象转换为字节序列的过程称为对象的序列化。 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
(2)实现:import java.io.Serializable;(注意:这个接口只用来标示,并没有实际的字段和方法)
The serialization interface has no methods or fields(没有字段和方法)
- and serves only to identify the semantics of being serializable.
2
3
4
> > ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("××××文件名")));
> > oos.writeObject(flyPig);
> >>
2
3
4
> > ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("××××××文件名")));
> >FlyPig person = (FlyPig) ois.readObject();
> >>
transient 修饰的属性,是不会被序列化的。
(3) serialVersionUID 的作用和用法?
就是在实现这个Serializable 接口的时候,一定要给这个 serialVersionUID 赋值
10.Java有几种文件拷贝方式?哪一种最高效?
(1)利用 java.io 类库,直接为源文件构建一个 FileInputStream 读取,然后再为目标文件构建一个FileOutputStream,完成写入工作.
(2)利用 java.nio 类库提供的transferTo 或 transferFrom方法实现。
(3)Java 标准类库本身提供了几种 Files.copy 的实现。(java.nio.file.Files.copy)

对于 Copy 的效率,这个其实与操作系统和配置等情况相关,总体上来说,NIO transferTo/From 的方式可能更快,因为它更能利用现代操作系统底层机制,避免不必要拷贝 和上下文切换。
11.FileInputStream在使用完以后,不关闭流,想二次使用可以怎么操作?
12.Reactor, Proactor?
13.Netty
Netty 是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现。它提供了对TCP、 UDP 和文件传输的支持,作为一个异步 NIO 框架, Netty 的所有 IO 操作都是异步非阻塞的, 通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。
(六)Java 8
1.接口的默认方法(Default Methods for Interfaces)
2.函数式接口(Functional Interfaces)@FunctionalInterface
3.Lamda 表达式作用域(Lambda Scopes)
4.java.util.Stream
Filter(过滤), Sorted(排序), Map(映射) , Match(匹配), Count(计数), Reduce(规约)
5.时间相关
(七)quartz和timer对比
(八)RPC
RPC(Remote Procedure Call)即远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?这个时候就需要 RPC 了! RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。
1. 设计一个RPC框架
一个完整的 RPC 框架使用示意图如下:
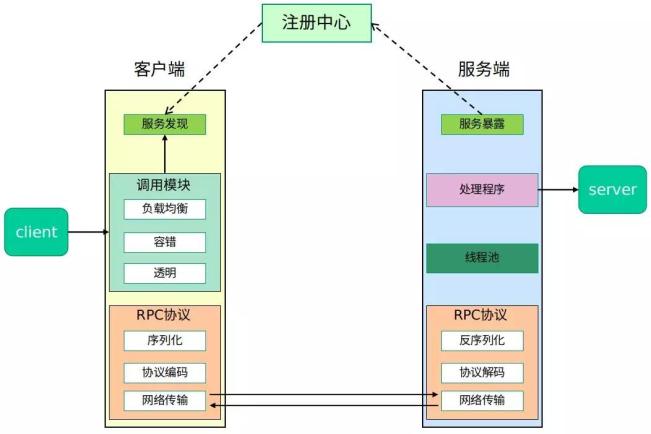
(1)注册中心
服务端启动的时候将服务名称及其对应的地址(ip+port)注册到注册中心,服务消费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消费端就可以通过网络请求服务端了。
(2)网络传输
既然我们要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的参数等数据到服务提供端。网络传输具体实现你可以使用 Socket ( Java 中最原始、最基础的网络通信方式。但是,Socket 是阻塞 IO、性能低并且功能单一)。你也可以使用同步非阻塞的 I/O 模型 NIO ,但是用它来进行网络编程真的太麻烦了。基于 NIO 的网络编程框架 Netty ,它将是你最好的选择!
(3)序列化
要在网络传输数据就要涉及到序列化 。所以,我们还要考虑选择哪种序列化协议。序列化方式有很多种,比较常见的有 hessian、kyro、protostuff ……。我会在下一篇文章中简单对比一下这些序列化方式。
(4)动态代理
RPC 的主要目的就是让我们调用远程方法像调用本地方法一样简单,使用动态代理屏蔽远程方法调用的细节比如网络传输。也就是说当你调用远程方法的时候,实际会通过代理对象来传输网络请求

